Tag: ideas-built (Atom feed)
Outcome Probability for One Handed Solitaire
Back in 1994 my circle of high school friends spent a lot of time sitting around talking (there were no cell phones) and for about a week we were all playing one handed solitaire. In suburban St. Louis we called it idiot's delight solitaire (which turns out to be an entirely different game), because there is absolutely no human input after the shuffle. As soon as you've started playing it's already determined whether you've won -- you just spend five minutes learning if you did.
Naturally we wondered how likely our very rare wins were, and being a computer nerd back then too I wrote a Pascal(!) program to simulate the game and arrived at the conclusion you win one in every 142 games.
Now thirty years later I've taught the game to the eleven year old in our home, who is just game back from a phone-free summer camp with a deck of cards and dubious shuffling skills.
My old Pascal is lost to bitrot, but the game as python, using a sort of janky off the shelf deck_of_cards module is trivial:
def play():
deck = deck_of_cards.DeckOfCards()
hand = []
while not deck._deck_empty():
hand.append(deck.give_random_card())
while len(hand) > 3:
if hand[-1].suit == hand[-4].suit:
del hand[-3:-1]
elif hand[-1].rank == hand[-4].rank:
del hand[-4:]
else:
break
return len(hand)
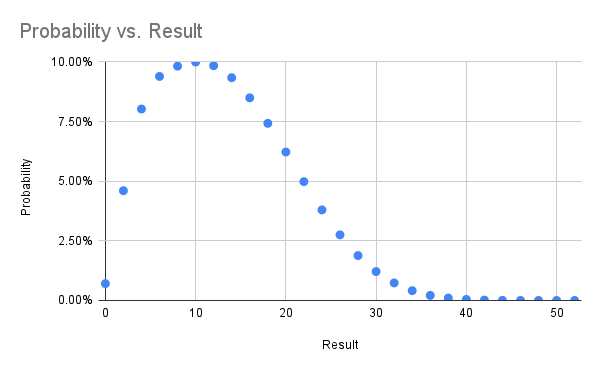
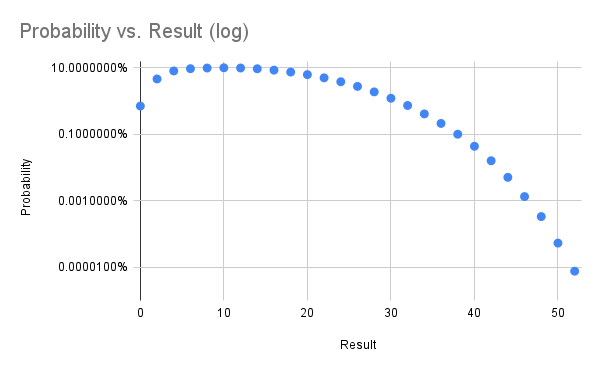
On the 486 I was running at the time I recall getting ten thousand or so runs over many days. On a tiny Linode in the modern era I got 50 million runs in 15ish hours.
I've gathered the results in a spreadsheet and included some probability graphs below. In trying to find the real name of this game I came across a previous analysis from 2014 which comes to the same overall probability. That blog post is now down (hence the archive.org links) with ominous messages telling folks the author is definitely no longer thinking about this game.
A Gamebook Report with Graphviz, Google Sheets, Python, and Juypter/Colab
An 11 year old in our house needed to do a book report for school in the form of a board game and selected a gamebook, apparently the generic name for the trademarked Choose Your Own Adventure books. The non-linear narrative made the choice of board layout easy -- just use the graph of pages-transitions ("Turn to page 110").
The graphviz library is always my first choice when I want to visualize nodes and edges, and the python graphviz module provides a convenient way to get data into a renderable graph structure.
I wanted to work with the 11 year old as much as possible, so I picked a programming environment that can be used anywhere, jupyter notebooks, and we ran it in Google's free hosted version called colab.
The data entry was going to be the most time consuming part of the project, and something we wanted to be able to work on both together and apart. For that I picked a Google sheet. It gave us the right mix of ease of entry, remote collaboration, and a familiar interface. Python can read from Google sheets directly using the gspread module, saving a transcription/import step.
It took us a few weeks of evenings to enter the book's info into the data spreadsheet. The two types of data we needed were places, essentially nodes, and decisions, which are edges. For every place we recorded starting page, a description of what happens, and the page where you next make a decision or reach an ending. For every decision we recorded the page where you were deciding, a description of the choice, and the page to which you'd go next. As you can see in the data spreadsheet that was 139 places/nodes and 177 decisions/edges.
Once we'd entered all the data we were able to run a short python program to load the data from the spreadsheet, transform it into a graph object, and then render that graph as a pdf file. That we printed with a large format printer, and then the 11 year old layered on art, puzzles, rules, and everything else that turns a digraph into a playable game. The final game board is shown below, with a zoomed section in the album.
One interesting thing about this particular book that was only evident once the full graph was in front of us was that the very first choice in the book splits you into one of two trees that never reconnect. Lots of later choices in the book loop back and cross over, but that first choice splits you into one of two separate books.
I've omitted the title and author info from the book to stop this giant spoiler from showing up on google searches, but the 11 year old assures me it was a good, fun read and recommends it.

Kindle Highlights and Ratings
When reading I've always underlined sentences that make me happy. Once the kids got old enough to understand there's no email or fun on a Kindle I switched from dead tree books, and now the underlining is stored in Amazon's datacenters.
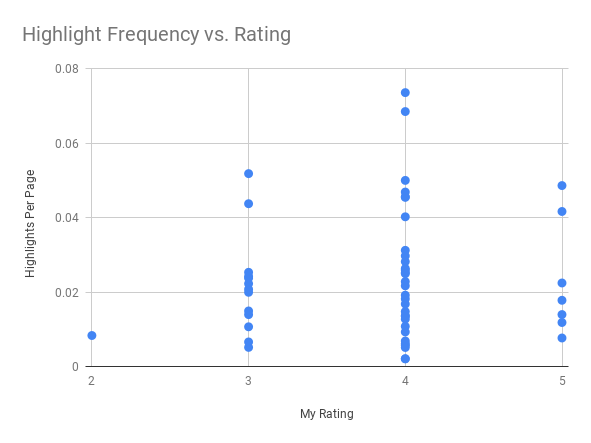
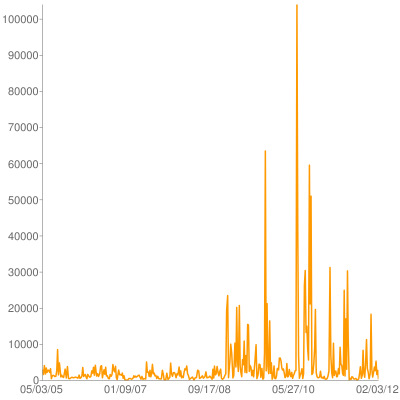
After a few years of highlighting on Kindle I started to wonder if the number of sentences that I liked and the eventual five-star scale rating I gave a book had any correlation. Amazon owns Goodreads and Kindle services sync data into Goodreads, but unfortunately highlight data isn't available through any API.
I was able to put together a little Python to scrape the highlight counts per book (yay, BeautifulSoup) and combine it with page count and rating info from the goodreads APIs. Our family scientist explained "the statistical tests to compare values of a continuous variable across levels of an ordinal variable", and there was no meaningful relationship. Still it makes a nice picture:
Home Alarm Analytics With AWS Kinesis
Home security system projects are fun because everything about them screams "1980s legacy hardware design". Nowhere else in the modern tech landscape does one program by typing in a three digit memory address and then entering byte values on a numeric keypad. There's no enter-key -- you fill the memory address. There's no display -- just eight LEDs that will show you a byte at a time, and you hope it's the address you think it is. Arduinos and the like are great for hobby fun, but these are real working systems whose core configuration you enter byte by byte.
The feature set reveals 30 years of crazy product requirements. You can just picture the well-meaning sales person who sold a non-existent feature to a huge potential customer, resulting in the boolean setting that lives at address 017 bit 4 and whose description in the manual is:
ON: The double hit feature will be enabled. Two violations of the same zone within the Cross Zone Timer will be considered a valid Police Code or Cross Zone Event. The system will report the event and log it to the event buffer. OFF: Two alarms from the same zone is not a valid Police Code or Cross Zone Event
I've built out alarm systems for three different homes now, and while occasionally frustrating it's always a satisfying project. This most recent time I wanted an event log larger than the 512 events I can view a byte at a time. The central dispatch service I use will sell me back my event log in a horrid web interface, but I wanted something programmatically accessible and ideally including constant status.
The hardware side of the solution came in the form of the Alarm Decoder from Nu Tech. It translates alarm panel keypad bus events into events on an RS-232 serial bus. That I'm feeding into a Raspberry Pi. From there the alarmdecoder package on PyPI lets me get at decoded events as Python objects. But, I wanted those in a real datastore.
Raspberry Pi UPS
I'm starting to do more on a raspberry pi I've got in the house, and I wanted it to survive short power outages. I looked at buying an off the shelf Uninteruptable Power Supply (UPS), but it just struck me as silly that I'd be using my house's 120V AC to power to fill a 12V DC battery to be run through an inverter into 120V AC again to be run through a transformer into DC yet again. When the house is out of power that seemed like a lot of waste.
A little searching turned up the PicoUPS-100 UPS controller. It seems like it's mostly used in car applications, but it has two DC inputs and one DC output and handles the charging and fast switching. The non-battery input needs to be greater than the desired 12 volts, so I ebayed a 15v power supply from an old laptop. I added a voltage regulator and buck converter to get solid 12v (router) and 5v (rpi) outputs. Then it caught on fire:

But I re-bought the charred parts, and the second time it worked just fine:

Pylint To Github
I spent a few hours trying to get the Jenkins Git & Github plugins to:
- run pylint on all remote branch heads that:
- arent' too old
- haven't already had pylint run on them
- send the repo status back to GitHub
I'm sure it's possible, but the Jenkins Git plugin doesn't like a single build to operate on multiple revisions. The repo statuses weren't posting, the wrong branches were getting built, and it was easier to write a quick script.
Now whenever someone pushes code at DramaFever pylint does its thing, and their most recent commit gets a green checkmark or a red cross. If/when they open a PR the status is already ready on the PR and warns folks not to merge it if pylint is going to fail the build. They can keep heaping on commits until the PR goes green.
I run it from Jenkins triggerd by a GitHub push hook, but it's setup so that even running it from cron on the minute is safe for those without a CI server yet.
Bitcoin Conversion In Google Spreadsheets
I've been using Charlie Lee's excellent Google Spreadsheet Bitcoin tracker sheet for awhile but it pulls data from a single exchange at a time and relies on the ordering of those exchanges on the bitcoinwatch.com site, which vary with volume.
I figured out I could get better numbers more reliably from bitcoinaverage.com, which (predictably) averages multiple exchanges over various time periods. They offer a great JSON API, but unfortunately Google spreadsheets only export JSON -- they don't have a function for importing it.
None the less I was able to fake it using a regex. You can pull the 24 hour average price in with this forumla:
=regexextract(index(importdata("https://api.bitcoinaverage.com/ticker/USD"),2,1), ": (.*),")+0
If you want that to update live (not just when you open the spreadsheet) you need to use Charlie's hack to get the sheet to think the formula depends on live stock data:
=regexextract(index(importdata("https://api.bitcoinaverage.com/ticker/USD?workaround="&INT(
NOW()*1E3)&REPT(GoogleFinance("GOOG");0)),2,1), ": (.*),")+0
I've put together a sample spreadsheet based on Charlie's.
Occuped: Twine + Go + App Engine
In our NY office We've got 40 people working in a space with two bathrooms. Walking to the bathrooms, finding them both occupied, and grabbing a snack instead is a regular occurrence. For a lark I took a Twine with the breakout board and a few magnetic switches and connected them to the over taxed bathroom doors.
The good folks at Twine will invoke a web hook on state change, so I created a tiny webapp in Go that takes the GET from Twine and stashes it in the App Engine datastore. I wrote a cheesy web front end to show the current state based on the most recent change. It also exposes a JSON API, allowing my excellent coworkers to build a native OS X menulet and a much nicer web version.

Crossed Lamps
Last weekend we bought two Rodd lamps at Ikea for the guest room, and it struck me how amused I'd be if each one switched the other. Six hours and a few new parts later, and it came out pretty well:
The remote action is especially jarring because the switches are right next to the bulbs they would normally control:

Amazon S3 as Append Only Datastore
As a hack, when I need an append-only datastore with no authentication or validation, I use Amazon S3. S3 is usually a read-only service from the unauthenticated web client's point of view, but if you enable access logging to a bucket you get full-query-parameter URLs recorded in a text file for GETs that can come from a form's action or via XHR.
There aren't a lot of internet-safe append-only datastores out there. All my favorite noSQL solutions divide permissions into read and/or write, where write includes delete. SQL databases let you grant an account insert without update or delete, but still none suggest letting them listen on a port that's open to the world.
This is a bummer because there are plenty of use cases when you want unauthenticated client-side code to add entries to a datastore, but not read or modify them: analytics gathering, polls, guest books, etc. Instead you end up with a bit of server side code that does little more than relay the insert to the datastore using over-privileged authentication credentials that you couldn't put in the client.
To play with this, first, create a file named vote.json in a bucket with contents like {"recorded": true}, make it world readable, set Cache-Control to max-age=0,no-cache and Content-Type to application/json. Now when a browser does a GET to that file's https URL, which looks like a real API endpoint, there's a record in the bucket's log that looks something like:
aaceee29e646cc912a0c2052aaceee29e646cc912a0c2052aaceee29e646cc91 bucketname [31/Jan/2013:18:37:13 +0000] 96.126.104.189 - 289335FAF3AD11B1 REST.GET.OBJECT vote.json "GET /bucketname/vote.json?arg=val&arg2=val2 HTTP/1.1" 200 - 12 12 9 8 "-" "lwp-request/6.03 libwww-perl/6.03" -
The full format is described by Amazon, but with client IP and user agent you have enough data for basic ballot box stuffing detection, and you can parse and tally the query arguments with two lines of your favorite scripting language.
This scheme is especially great for analytics gathering because and one never has to worry about full log on disks, load balancers, backed up queues, or unresponsive data collection servers. When you're ready to process the data it's already on S3 near EC2, AWS Data Pipeline or Elastic MapReduce. Plus, S3 has better uptime than anything else Amazon offers, so even if your app is down you're probably recording the failed usage attempts.
Creating Burn Down Charts for GitHub Repositories Using Google Apps Script
At DramaFever I got folks to buy into to burn down charts as the daily display for our weekly sprints with the rotating release person being responsible for updating a Google spreadsheet with each day's end-of-day open and closed issue counts.
It works fine, and it's only a small time burden, but if one forgets there's no good way to get the previous day's counts. Naturally I looked to automation, and GitHub has an excellent API. My usual take on something like this would be to have cron trigger a script that:
- polls the GitHub API
- extracts the counts
- writes them to some data store
- builds today's chart from the historical data in the datastore
That could be easily done in bash, Python, or Perl, but it's the sort of thing that's inevitably brittle. It's too ad hoc to run on a prod server, so it'll run from a dev shell box, which will be down, or disk full, or rebuilt w/o cron migration or any of the million other ailments that befall non-prod servers.
Looking for something different I tried Google Apps Script for the first time, and it came out very well.
GitHub Jenkins Deploy Keys Config
GitHub doesn't let you use the same deploy key for multiple repositories within a single organziation, so you have to either (a) manage multiple keys, (b) create a non-human user (boo!), or (c) use their not-yet-ready for primetime HTTP OAUTH deploy access, which can't create read-only permissions.
In the past to managee the multiple keys I've either (a) used ssh-agent or (b) specified which private key to use for each request using -i on the command line, but neither of those are convenient with Jenkins.
Today I finally thought about it a little harder and figured out I could use fake hostnames that map to the right keys within the .ssh/config file for the Jenkins user. To make it work I put stanzas like this in the config file:
Host repo_name.github.com
Hostname github.com
HostKeyAlias github.com
IdentityFile ~jenkins/keys/repo_name_deploy
Then in the Jenkins GitHub Plugin config I set the repository URL as:
git@repo_name.github.com:ry4an/repo_name.git
There is no host repo_name.github.com and it wouldn't resolve in DNS, but that's okay because the .ssh/config tells ssh to actually go to github.com, but we do get the right key.
Maybe this is obvious and everyone's doing it, but I found it the least-hassle way to maintain the accounts-for-people-only rule along with the separate-keys-for-separate-repos rule and without running the ssh-agent daemon for a non-login shell.
spdyproxy on Ubuntu 12.4 LTS
I'm often on unencrypted wireless networks, and I don't always trust everyone on the encrypted ones, so I routinely run a SOCKS proxy to tunnel my web traffic through an encrypted SSH tunnel. This works great, but I have to start the SSH tunnel before I start browsing -- that's okay IRC before reader -- but when I sleep the laptop the SSH tunnel dies and requires a restart before I can browse again. In the past I've used autossh to automate that reconnect, but it still requires more attention than it deserves.
So I was excited when I saw Ilya Grigorik's writeup on spdyproxy. With SPDY multiple independent bi-directional connections are multiplexed through a single TCP connection, in the same way some of us tried to do with web-mux in the late 90s (I've got a Java 1.1 implementation somwhere). SPDY connections can be encrypted, so when making a SPDY connection to a HTTP proxy you're getting an encrypted tunnel though which your HTTP connections to anywhere can be tunneled, and probably getting a TCP setup/teardown speed boost as well. Ilya's excellent node-spdyproxy handles the server side of that setup admirably and the rest of this writeup covers my getting it running (with production accouterments) on an Ubuntu 12.4(.1) LTS system.
With the below setup in place I can use a proxy.pac to make sure my browser never sends an unencrypted byte through whatever network I'm not -- DNS looksups excluded, you still needs SOCKSv4a or SOCKSv5 to hide those.
Getting Chef Solo Working With the Database Cookbook and Vagrant
This is going to be one big jargon laden blob if you're not trying to do exactly what I was trying to do this week, but hopefully it turns up in a search for the next person.
I'm setting up a new development environment using Vagrant and I'm using Chef Solo to provision the Ubuntu (12.4 Precise Penguin) guest. I wanted MySQL server running and wanted to use the database cookbook from Opscode to pre-create a database.
My run list looked like:
recipe[mysql::server], recipe[webapp]
Where the webapp recipe's metadata.rb included:
depends "database"
and the default recipe led off with:
mysql_database 'master' do connection my_connection action :create end
Which would blow up at execution time with the message "missing gem 'mysql'", which was really frustrating because the gem was already installed in the previous mysql::server recipe.
I learned about chef_gem as compared to gem_package from the chef docs, and found another page the showed how to run actions at compile time instead of during chef processing, but only when I did both like this:
%w{mysql-client libmysqlclient-dev make}.each do |pack|
package pack do
action :nothing
end.run_action(:install)
end
g = chef_gem "mysql" do
action :nothing
end
g.run_action(:install)
was I able to get things working. Notice that I had to install the OS packages for mysql, the mysql development headers, and the venerable make because I could early install the mysql ruby gem into chef's gem path -- which with Vagrant's chef solo provisioner is entirely separate from any system gems.
Low Flow Shower Delay
When I start up the shower it's the wrong temperature and adjusting it to the right temperature takes longer in this apartment than it has in any home in which I've previously lived. I wanted to blame the problem on the low flow shower head, but I'm having a hard time doing it. My thinking was that the time delay from when I adjust the shower to when I actually feel the change is unusually high due to the shower head's reduced flow rate.
In setting out to measure that delay I first found the flow rate in liters per second for the shower. I did this three times using a bucket and a stopwatch finding the shower filled 1.5 qt in 12 s, or 1.875 gpm, or 0.118 liters per second. A low flow shower head, according to the US EPA's WaterSense program, is under 2.0 gpm, so that's right on target.
That let me know how quickly the "wrong temperature" water leaves the pipe, so next to see how much of it there is. From the hot-cold mixer to the shower head there's 65 inches of nominal 1/2" pipe, which has an inner diameter of 0.545 inches. The volume of a cylinder (I'm ignoring the curve of the shower arm) is just pi times radius squared times length:
Converting to normal units gives 1.3843 centimeters diameter and 165.1 centimeters length, which yeilds 248 cm2, or 0.248 liters, of wrong temperature water to wait through until I get to sample the new mix.
With a flow rate of 0.118 liters per second and 0.248 liters of unpleasant water I should be feeling the new mix in 2.1 seconds. I recognize that time drags when you're being scalded, but it still feels like longer than that.
I've done some casual reading about linear shift time delays in feedback-based control systems and the oscillating converge they show certainly aligns with the too-hot then too-cold feel of getting this shower right. This graph is swiped from MathWorks and shows a closed loop step response with a 2.5 second delay:
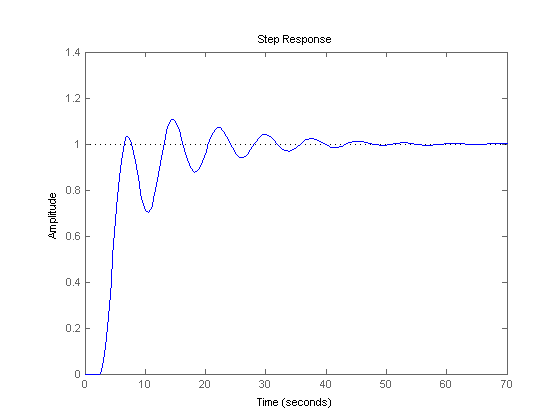
That shows about 40 seconds to finally home-in on the right temperature and doesn't include a failure-prone, over-correcting human. I'm still not convinced the delay is the entirety of the problem, but it does seem to be a contributing factor. Some other factors that may affect perception of how show this shower is to get right are:
- non-linearity in the mixer
- water in the shower head itself
- water already "in flight" having left the head but not yet having hit me
Mercifully, the water temperature is consistent -- once you get it dialed in correctly it stays correct, even though a long shower.
I guess the next step is to get out a thermometer and both try to characterize the linearity of the mixing control and to try to measure rate of change in the temperature as related to the magnitude of the adjustment.
Update: I got a ChemE friend to weigh in with some help.
OS X Linux Clipboard Sharing
My primary home machine is a Linux deskop, and my primary work machine is an OSX laptop. I do most of my work on the Linux box, ssh-ed into the OS X machine -- I recognize that's the reverse of usual setups, but I love the awesome window manager and the copy-on-select X Window selection scheme.
My frustration is in having separate copy and paste buffers across the two systems. If I select something in a work email, I often want to paste it into the Linux machine. Similarly if I copy an error from a Linux console I need to paste it into a work email.
There are a lot of ways to unify clipboards across machines, but they're all either full-scale mouse and keyboard sharing, single-platform, or GUI tools.
Finding the excellent xsel tool, I cooked up some command lines that would let me shuttle strings between the Linux selection buffer and the OS X system via ssh.
I put them into the Lua script that is the shortcut configuration for awesome and now I can move selections back and forth. I also added some shortcuts for moving text between the Linux selection (copy-on-select) and clipboard (copy-on-keypress) clipboard.
-- Used to shuttle selection to/from mac clipboard
select_to_mac = "bash -c '/usr/bin/xsel --output | ssh mac pbcopy'"
mac_to_select = "bash -c 'ssh mac pbpaste | /usr/bin/xsel --input'"
-- Used to shuttle between selection and clipboard
select_to_clip = "bash -c '/usr/bin/xsel --output | /usr/bin/xsel --input --clipboard'"
clip_to_select = "bash -c '/usr/bin/xsel --output --clipboard | /usr/bin/xsel --input'"
awful.key({ modkey, }, "c", function () awful.util.spawn(mac_to_select) end),
awful.key({ modkey, }, "v", function () awful.util.spawn(select_to_mac) end),
awful.key({ modkey, "Shift" }, "c", function () awful.util.spawn(clip_to_select) end),
awful.key({ modkey, "Shift" }, "v", function () awful.util.spawn(select_to_clip) end),
NFC PayPass Rick Roll
NFC tags are tiny wireless storage devices, with very thin antennas, attached to poker chip sized stickers. They're sort of like RFID tags, but they only have a 1 inch range, come in various capacities, and can be easily rewritten. If the next iPhone adds a NFC reader I think they'll be huge. As it is they're already pretty fun and only a buck each even when bought in small quantities.
Marketers haven't figured it out yet, but no one wants to scan QR barcodes. The hassle with QR codes is that you have to fire up a special barcode reader application and then carefully focus on the barcode with your phone's camera. NFC tags have neither of those problems. If your phone is awake it's "looking for" NFC tags, and there's no aiming involved -- just tap your phone on the tag.
A NFC tag stores a small amount of data that's made available to your phone when tapped. It can't make you phone do anything your phone doesn't already do, and your phone shouldn't be willing to do anything destructive or irreversible (send money) without asking for your confirmation.
People are using NFC tags to turn on bluetooth when their phone is placed in a stickered cup-holder, to turn off their email notification checking when their phone is placed on their nightstand, and to bring up their calculator when their phone is placed on their desk. Most anything your phone can do can be triggered by a NFC tag.
NFC tags are already in use for transit passes, access keys, and payment systems. I can go to any of a number of businesses near my home and make a purchase by tapping my phone against the Master Card PayPass logo on the card scanner. My phone will then ask for a pin and ask me to confirm the purchase price which is deducted from my Google Wallet or charged to my Citi MasterCard.
I'm still batting around ideas for a first NFC project, maybe a geocaching / scavenger-hunt-like trail of tags with clues, but meanwhile I made some fake Master Card PayPass labels that are decidedly more fun:
Keep in mind that phone has absolutely no non-standard software or settings on it. Any NFC-reader equipped phone that touches that tag will be rick rolled. Now to get a few of those out on local merchants' existing credit card readers.
Mercurial Chart Extension
Back in 2008 I wote an extension for Mercurial to render activity charts like this one:
Yesterday I finally got around to updating it for modern Mercurial builds, including 2.1. It's posted on bitbucket and has a page on the Mercurial wiki. It uses pygooglechart as a wrapper around the excellent Google image chart API.
I really like the google image charts becuse the entire image is encapsulated as a URL, which means they work great with command line tools. A script can output a URL, my terminal can make it a link, and I can bring it up in a browser window w/o ever really using a GUI tool at all.
If I take any next step on this hg-chart-extension it will be to accept revsets for complex secifications of what changesets one wants graphed, but given that it took me two years to fix breakage that happened with version 1.4 that seems unlikely.
Minneapolis Surveillance Camera Project Shut Down
Now that I no longer live in Minneapolis it seems a fine time to shut down the Minneapolis Surveilance Camera Project I launched in 2003.
At peak it got mentioned in a few strib articles, was written about in the downtown journal, and got a lot of hits from computers within city and county government. After my initial inventory walk most of the camera additions came in via the website from strangers. More of the reports had photos of the cameras once everyone had a camera in their phone.
The whole idea of trying to inventory public and private cameras in public spaces seems silly now. One might as well start the Minneapolis Atom Inventory project -- they're just as plentiful and hard to spot.
If anyone would like the mpls-watched.org domain for any reason let me know. It expires in June and I'm happy to transfer it to someone with a use for it. The content still exists within archive.org.
Posthumous Key Revocation
I've just emptied out my safe deposit box for the move, and thought I'd re-post this:
If you hear I've died someone who knows their way around gpg should ask Kate for the CD pictured below. It'll be in a safe deposit box that's in my name, and she'll have access after my death. There's a key revocation certificate with reason 'death' on the CD and a printed ASCII-armored version too since the odds of us being able to read CDs in a few decades is approximately nil.

Miscellaneous Open Source Contributions
I'll take Mercurial over git any day for all the reasons obvious to anyone who's really used both of them, but geeyah github sure makes contributing to projects easy. At work we had a ten minute MongoDB upgrade downtime turn into two hours, and when we finally figured out what deprecated option was causing the daemon launch to abort, rather than grouse about it on Twitter (okay, I did that too) I was able to submit a one line patch without even cloning down the repository that got merged in.
On the more-substantial side I fixed some crash bugs in dircproxy. It had been running rock solid for me for a few years, but a recent libc upgrade that added some memory checking had it crashing a few times a day. Now (with the help of Nick Wormley) I was able to fix some (rather egregious) memory gaffs. I guess this is the oft trumpeted advantage of open source software in the first place -- I had software I counted on that stopped working and I was able to fix. Really though it was just fun to fire up gdb for the first time in ages.
Finally, I was able to take some hours at work and contribute a cookbook for chef to add the New Relic monitoring agent to our many ec2 instances. It may never see a single download, but it's nice to know that if someone wants to use chef to add their systems to the New Relic monitoring display they don't have to start from scratch.
I've been living in a largely open source computing environment for fifteen years, but the barrier to entry as minor contributor has never been so low.
Ancient Content Warnings
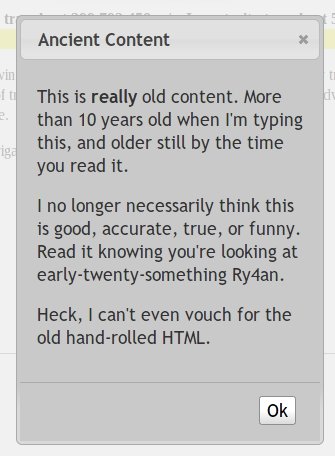
I just rebuilt the ry4an.org server, and as part of the migration I realized a still had a lot of very old, almost embarrassing content online. I took the broken or not-conceivably interesting stuff off-line and am serving up 410 GONE responses for it.
There exists, however, a broad swath of stuff that's not yet entirely useless, but is more than ten years old and not stuff I would likely post today. For all of these pages I've left the content up, but you first have to click through a modal dialog warning you you're looking at very old stuff I don't necessarily endorse. That pop up looks like this:
An example can be found here: https://ry4an.org/rrr/ . (Though, if anyone still wants to race from point to point in the twin cities during the worst of rush hour I still think it's an awesome idea.)
Being the sort of person that I am I automated the process of adding those warnings to anything that hasn't been modified in at least 10 years. So, if you got an ancient content warning when viewing this page: Hello 2021!
If you follow a link or bookmark to ry4an.org and you get a 404 Not Found, let me know. Everything should either still be there or should give a 410 GONE so you know it's not there on purpose.
Asynchronous Python Logging
The Python logging module has some nice built-in LogHandlers that do network IO, but I couldn't square with having HTTP POSTs and SMTP sends in web response threads. I didn't find an asynchronous logging wrapper, so I wrote a decorator of sorts using the really nifty monkey patching availble in python:
def patchAsyncEmit(handler):
base_emit = handler.emit
queue = Queue.Queue()
def loop():
while True:
record = queue.get(True) # blocks
try :
base_emit(record)
except: # not much you can do when your logger is broken
print sys.exc_info(
thread = threading.Thread(target=loop)
thread.daemon = True
thread.start(
def asyncEmit(record):
queue.put(record)
handler.emit = asyncEmit
return handler
In a more traditional OO language I'd do that with extension or a dynamic proxy, and in Scala I'd do it as a trait, but this saved me having to write delegates for all the other methods in LogHandler.
Did I miss this in the standard logging stuff, does everyone roll their own, or is everyone else okay doing remote logging in a web thread?
Graduation Form Letter
We just passed through another graduation season, and for the second year running I was able to get by with the same stack of form letters:
Dear _______________________________, My ( Congratulations | Condolences | ___________________ ) on your recent ( Graduation | Eagle Rank | Loss | ___________________ ). It is with ( Great Joy | a Heavy Heart ) that I received the news. I'm sure it took a lot of ( Hard Work | Cigarettes ) to make it happen. I'm sure you'll have a ( great time | good cry ) at the ( open house | wake ) and ( regret | am glad) that I ( can | cannot ) attend. As you move on to your next phase in life please remember: [ ] the importance of hard work [ ] the risks of smoking [ ] there are other fish in the sea [ ] don't have your mom send out your graduation invites -- you're an adult now [ ] ________________________________________ and the value of personal correspondence. Sincerely, your (Cousin | Scoutmaster | Parolee | _____________________), Ry4an Brase Enclosures (1): ( Check | Card | Gift | Best Wishes )
It's available as a Google Doc.
Scholars Walk Time Traveller
The University of Minnesota has a Scholar's Walk which celebrates great persons affiliated with the U and the awards they've won. One display labeled "Historical Giants" remains without any names. Since the U can't reasonably be anticipating any new history, I imagine that four years after installation there's still a committee somewhere arguing about which department gets more names. Not content to wait for committee I decided to add a historical giant of my own -- a time traveller.

The displays are stone boxes with two panes of glass. The outermost pane of glass extends a quarter inch on steel pegs and shows the University branding and the category information. The innermost pane is recessed three inches and contains the names of the honorees. I figured that the outermost glass would provide the necessary gloss, and that any way I could get names behind it and at the right depth would look okay.
I had vinyl lettering made with the wording I wanted and applied it to some laboriously-cut thin lexan. In tests I could I could bend the lexan ninety degrees with just a four inch radius. That flexibility was enough that I could slide the insert in the bottom of the display (the top was sealed against weather).
I showed up early one morning, slipped the insert into place between the two pieces of glass, and was very pleased with the result. The white lettering looked sufficiently etched once behind the shiny outer glass, the fonts and sizes matched nearby displays, and the borders of the lexan insert were nearly invisible. The text is easier to read in the big photo links below, but it lists a physicist with a dis-joint lifespan lauded "for her uniquely important contributions to the understanding of time travel".
Sadly, the insert was removed a few months later, and before someone who can actually take a decent picture got to it. Removing it probably meant disassembling the box to some extent as the very springy plastic insert wouldn't adopt the bend required to make it around the corner without significant coercion not applicable from out side the box.
Here are the bigger pics:
{kind=link}
{kind=link}
Homemade Tonic
I just made my third batch of tonic water from Mark Sexauer's Recipe:
- 4 cups water
- 4 cups sugar
- 1/4 cup cinchona bark
- 1/4 cup citric acid
- Zest and juice of 1 lime
- Zest and juice of 1 lemon
- Zest and juice of 1 orange
- 1 teaspoon coriander seeds
- 1 teaspoon dried bitter orange peel
- 10 dashes bitters
- 1 hand crushed juniper berry (I used two)
The flavor is excellent, but the process is terrible. Specifically, filtering the cinchona bark from the mixture after extracting the quinine (actually totaquine) from it is nearly impossible. It's so finely ground it clogs any filter, be it paper or the mesh on a french press coffeemaker, almost immediately. I've tried letting it settle and pouring off the liquid, forcing the liquid through with back pressure, and letting it drip all night -- none work well. A friend using the same recipe build a homemade vacuum extractor, but I've not yet gone that far.
This time I used multiple coffee filters and gravity, changing out the filter after each few tablespoons of water flowed through and the filter was plugged. I lost about half the liquid volume in the form of discarded, soggy filters. On previous batches I didn't take the liquid loss into account when adding sugar, yielding tonic water that was too sweet -- my primary complaint with store bought tonic --, but this time I halved the sugar as well and got a nice tart result. The fresh citrus and two juniper berries I use make it a perfect match for a nice gin. I'm able to carbonate the mixture with my own carbonation rig.
For the next batch I'm going to see if I can buy some quinine from the gray market online pharmacies. A single 300mg tablet, used to fight malaria or alleviate leg cramps, will make three strong liters and I'll be able to skip the filtering process entirely. The other benefit to using quinine instead of totaquine is aesthetic. The cinchona bark leaves my homemade tonic syrup brown and the water an unpleasant yellow color as you can see below.

A Few Quick EC2 Security Group Migration Tools
Like half the internet I'm working on duplicating a setup from one Amazon EC2 availability zone to another. I couldn't find a quick way to do that if my stuff wasn't already described in Cloud Formation templates, so I put together a script that queries the security groups using ec2-describe-group and produces a shell script that re-creates them in a different region.
If all your ec2 command line tools and environment variables are set you can mirror us-east-1 to us-west-1 using:
ec2-describe-group | ./create-firewall-script.pl > create-firewall.sh ./create-firewall.sh
With non-demo security group data I ran into some group-to-group access grants whose purpose wasn't immediately obvious, so I put together a second script using graphviz to show the ALLOWs. A directed edge can be read as "can access".
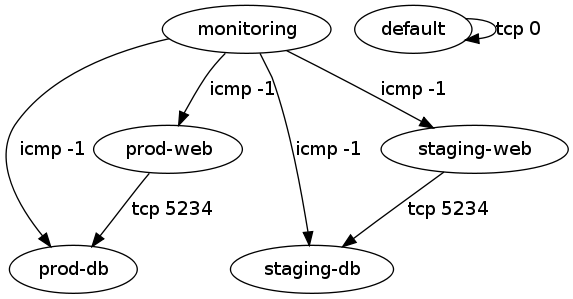
That script can also be invoked as:
ec2-describe-group | ./visualize-security-groups.pl > groups.png
The labels on the edges can be made more detailed, but having each of tcp, udp, and icmp shown started to get excessive.
Both scripts and sample input and output are in the provided tarball.
reStructuredText Resume
I've had a resume in active maintenance since the mid 90s, and it's gone through many iterations. I started with a Word document (I didn't know any better). In the late 90s I moved to parallel Word, text, and HTML versions, all maintained separately, which drifted out of sync horribly. In 2010 I redid it in Google Docs using a template I found whose HTML hinted at a previous life in Word for OS X. That template had all sorts of class and style stuff in it that Google Docs couldn't actually edit/create, so I was back to hand-editing HTML and then using Google Docs to create a PDF version. I still had to keep the text version current separately, but at least I'd decided I didn't want any job that wanted a Word version.
When I decided to finally add my current job to my resume, even months after starting, I went for another overhaul. The goal was to have a single input file whose output provided HTML, text, and PDF representations. As I saw it that made the options: LaTeX, reStructuredText, or HTML.
I started down the road with LaTeX, and found some great templates, articles, and prior examples, but it felt like I was fighting with the tool to get acceptable output, and nothing was coming together on the plain text renderer front.
Next I turned to reStructuredText, and found it yielded a workable system. I started with Guillaume ChéreAu's blog post and template and used the regular docutils tool rst2html to generate the HTML versions. The normal route for turning reStructuredText into PDF using doctools passes through LaTeX, but I didn't want to go that route, so I used rst2pdf, which gets there directly. I counted the reStructuredText version as close-enough to text for that format.
Since now I was dealing entirely with a source file that compiled to generated outputs it only made sense to use a Makefile and keep everything in a Mercurial repository. That gives me the ability to easily track changes and to merge across multiple versions (different objectives) should the need arise. With the Makefile and Mercurial in place I was able to add an automated version string/link to the resume so I can tell from a print out which version someone lis looking at. Since I've always used a source control repository for the HTML version it's possible to compare revisions back to 2001, which get pretty silly.
I'm also proud to say that the URL for my resume hasn't changed since 1996, so any printed version ever includes a link to the most current one. Here are links to each of those formats: HTML, PDF, text, and repository, where the text version is the one from which the others are created.
Automatic SSH Tunnel Home As Securely As I Can
After watching a video from Defcon 18 and seeing a tweet from Steve Losh I decided to finally set up an automatic SSH tunnel from my home server to my traveling machines. The idea being that if I leave the machine somewhere or it's taken I can get in remotely and wipe it or take photos with the camera. There are plenty of commercial software packages that will do something like this for Windows, Mac, and Linux, and the highly-regarded, open-source prey, but they all either rely on 3rd party service or have a lot more than a simple back-tunnel.
I was able to cobble together an automatic back-connect from laptop to server using standard tools and a lot of careful configuration. Here's my write up, mostly so I can do it again the next time I get a new laptop.
BoingBoing Posts in Rogue
Previously I mentioned I was importing the full corpus of BoingBoing posts into MonogoDB, which went off without a hitch. The import was just to provide a decent dataset for trying out Rogue, the Mongo searching DSL from the folks at Foursquare. Last weekend I was in New York for the Northeast Scala Symposium and the Foursquare Hackathon, so I took the opportunity finish up the query part while I had their developers around to answer questions.
Loading BoingBoing into MongoDB with Scala
I want to play around with Rogue by the Foursquare folks, but first I needed a decent sized collections of items in a MongoDB. I recalled that BoingBoing had just released all their posts in a single file, so I downloaded that and put together a little Scala to convert from XML to JSON. The built-in XML support in Scala and the excellent lift-json DSL turned the whole thing into no work at all:
Syntax Highlighting and Formulas for Blohg
I'm thus far thrilled with blohg as a blogging platform. I've got a large post I'm finishing up now with quite a few snippets of source code in two different programming languages. I was hoping to use the excellent SyntaxHighlighter javascript library to prettify those snippets, and was surprised to find that docutils reStructuredText doesn't yet do that (though some other implementations do).
Fortunately, adding new rendering directives to reStructuredText is incredibly easy. I was able to add support for a .. code mode with just this little bit of Python:
Blacklisting Changesets in Mercurial
Distributed version control systems have revolutionized how software teams work, by making merges no longer scary. Developers can work on a feature in relative isolation, pulling in new changes on their schedule, and providing results back on their (manager's) timeline.
Sometimes, however, a developer working in their own branch can do something really silly, like commit a huge file without realizing it. Only after they push to the central repository does the giant size of the changeset become known. If one catches it quickly, one just removes the changeset and all is will.
If other developers have pulled that giant changeset you're in a slightly harder spot. You can remote it from your repository and ask other developers to do the same, but you can't force them to do so. Unwanted changesets let loose in a development group have a way of getting pushed back into a shared repository again and again.
To ban the pushing of a specific changeset to a Mercurial repository one can use this terse hook in the repository's .hg/hgrc file:
[hooks] pretxnchangegroup.ban1 = ! hg id -r d2cfe91d2837+ /dev/null 2>&1
Where d2cfe91d2837 is the node id of the forbidden changeset.
That's fine for a single changeset, but if you more than a few to ban this form avoids having a hook per changeset:
[hooks]
pretxnchangegroup.ban = ! hg log --template '{node|short}\n' \
-r $HG_NODE:tip | grep -q -x -F -f /path/to/banned
where banned /path/to/banned is a file of disallowed changesets like:
acd69df118ab 417f3c27983b cc4e13c92dfa 6747d4a5c45d
It's probably prohibitively hard to ban changesets in everyone's repositories, but at least you can set up a filter on shared repositories and publicly shame anyone who pushes them.
Switching Blogging Software
This blog started out called the unblog back when blog was a new-ish term and I thought it was silly. I'd been on mailing lists like fork and Kragan Sitaker's tol for years and couldn't see a difference between those and blogs. I set up some mailing list archive software to look like a blog and called it a day.
Years later that platform was aging, and wikis were still a new and exciting concept, so I built a blog around a wiki. The ease of online editing was nice, though readers never took to wiki-as-comments like I hoped. It worked well enough for a good many years, but I kept having a hard time finding my own posts in Google. Various SEO-blocking strategies Google employs that I hope never to have to understand were pushing my entries below total crap.
Now, I've switched to blohg as a blogging platform. It's based on Mercurial my version control system of choice and has a great local-test and push to publish setup. It uses ReStructured-Text which is what wiki text became and reads great as source or renders to HTML. Thanks to Rafael Martins for the great software, templates, and help.
The hardest part of the whole setup was keeping every URL I've ever used internally for this blog still valid. URLs that "go dead" are a huge pet peeve of mine. Major, should-know-better sites do this all the time. The new web team brings up brand new site, and every URL you'd bookmarked either goes to a 404 page or to the main page. URLs are supposed to be durable, and while it's sometimes a lot of work to keep that promise it's worth it.
In migrating this site I took a couple of steps to make sure URLs stayed valid. I wrote a quick script to go through the HTTP access logs site for the last few months, looked for every URL that got a non-404 response, and turned them into web requests and made sure that I had all the redirects in place to make sure the old URLs yielded the same content on the staging site. I did the same essential procedure when I switched from mailing list to wiki so I had to re-aim all those redirects too. Finally, I ran a web spider against the staging site to make sure it had no broken internal links. Which is all to say, if you're careful you can totally redo your site without breaking people's bookmarks and search results -- please let me know if you find a broken one.
Mercurial Remote Test Runner via Push
I heard someone in IRC saying that the mercurial test suite was bogging down theirlaptop, so I set up a quick push-test service for the mercurial crew. If you're in crew and you do a push to ssh://hgtester@ry4an.org:2222/ these steps will be taken:
- a local clone of the crew repo is updated from intevention.de
- a new, disposable local clone is created from that crew clone
- your csets are pushed to that new clone
- the working directory is updated to 'tip'
- a build is done
- the test suite is run
- the build and results show up in your stdout
- the new clone (and your pushed csets) are deleted
It's on a reasonably fast, unloaded box so the test suite runs in about 3 mins 30 seconds. Thanks to ThomasAH for providing the crew pubkeys. If you're not in crew and want to use the service please contact me and convince me you're not going to write a test that does a "rm -rf ~", because that would completely work.
Unfortunately, the output is getting buffered somewhere so there's no output after "searching for changes" for almost 4 minutes, but the final output looks as attached.
The machine's RSA host key fingerprint is: ac:81:ac:0b:47:f4:20:a1:4d:7e:6a:c5:62:ba:62:be. (updated 2010/06/07)
The scripts can be viewed here: http://bitbucket.org/Ry4an/hgtester/
If all that was jibberish, we now return you to your regularly scheduled silence.
Remote Repository Creation for Mercurial Over HTTP
I park in the #mercurial IRC channel a lot to answer the easy questions, and on that comes up often is, "How can I create a remote repository over HTTP?". The answer is: "You can't.".
Mercurial allows you to create a repository remotely using ssh with a command line like this:
hg clone localrepo ssh://host//abs/path
but there's no way to do that over HTTP using either hg serve or hgweb behind Apache.
I kept telling people it would be a very easy CGI to write, so a few months back I put my time where my mouth was and did it.:
#!/bin/sh echo -n -e "Content-Type: text/plain\n\n" mkdir -p /my/repos/$PATH_INFO cd /my/repos/$PATH_INFO hg init
That gets saved in unsafecreate.cgi and pointed to by Apache like this:
ScriptAlias /unsafecreate /path/to/unsafecreate.cgi
and you can remotely invoke it like this:
http://your-poorly-admined-host.com/unsafecreate/path/to/new/repo
That's littered with warning about its lack of safety and bad administrative practices because you're pretty much begging for someone to do this:
http://your-poorly-admined-host.com/unsafecreate/something%3Brm%20-rf%20
Which is not going to be pretty, but on a LAN maybe it's a risk you can live with. Me? I just use ssh.
At the time I first suggested this someone chimed in with a cleaned up version in the original pastie, but it's no safer.
Grand Central Direct Dialer
I'm a huge fan of Grand Central's call screening features. It's irksome, however, that they make it hard to dial outward -- sending your GC number instead of your cell number as the caller id. To do so you need to first add the target number to your address book, and often I'm calling someone I don't intend to call again often.
I started scripting up a way around that when I saw someone named Stewart already had.
I wanted to be able to easily dial outbound from my cellphone, so I created a mobile friendly web form around his script. The script requires info you should never give out (username, password, etc.), so you should really download the script and run it on your own webserver.
It also generates a bookmarklet you can drag to your browser's toolbar that will automatically dial any selected/highlighted phone number from your GC Number.
Comments
Only to save someone else the time: The iPhone app, Grand Dialer, does the same thing from an iPhone. Everyone says it's excellent.
Sasha Megan Bauer Brase
On July 29th, Kate gave birth to Sasha Megan Bauer Brase. Details and photos are on her site.
Comments
Is the Jerry Farber piece, an anthem of my youth, not copyrighted? Do you have permission? Where can I reach Farber? -- Some Random Person
Presumably you're referring to this, though I've no idea why you attached the comment to my daughter's birth announcement. I typed this from a blurry photocopy twenty years ago. If the copyright holder objects, I'll happily remove it.
Home Carbonator
Last year I read about home carbonation, and looking at the amount of club soda Kate and I buy it made sense. The only unknown was where to put the ugly tank that would be out of sight yet still convenient to use.
Months later coworkers and I were at the Red Stag, which carbonates their own sparkling water, and talked about doing the same at the office. I still didn't act until a friend got a soda club machine as a gift.
This weekend I (or actually Kate since I was running late) went to Northern Brewer and picked up parts K003, KX03, and K026 to build the setup below. It really does work as easy as the first article promises, and the price including the purchase of a tank came to $200 total. So far the best thing we've carbonated was orange juice, but I'm looking to try some fruit purees soon.

Misc. Projects Including A Baby
To look at this long neglected unblog one would thing I've stopped doing things, but quite the contrary there's been so very much doing of things that there's been no time for posting. In no particular order we have:
- Installed a home security system -- No particular need, but I've always enjoyed alarms and now our home has an RSS feed
- Installed an electric garage door opener -- No more brushing off the car in the morning after a snow. Granted it's still powered by an extension cord running from the basement, but hey so goes it.
- Installed nifty iButton electronic locks -- Now the same key opens every door to which I've got access including the Swarmcast offices.
- Un-finshed the basement -- wool insulation and moisture: a winning combination. The project included a fun trip to the city trash transfer station.
- Remodeled the kitchen -- I did almost no actual labor on this excepting some tile installation with Kate, the adding of rolley shelves in the pantry, and having to eat out for four straight months.
Add to those minor projects some time spent on general upkeep of an 85 year old home, scouts and a decidedly non-zero number of hours spent at work, and it becomes clear that what Kate and I need is a baby.
Kate's due on July 28th, and we're very excited.
Comments
Mazel tov on the baby news!
I happy to see that people from past who I have not kept up with in such a long time are living enjoyable and exciting lives!
-Mark Reck
You know how I have a strong distaste for breeding, and the products of breeding, but I suppose my stance has softened a little since several friends have produced, as far as I can tell, all together not terrible offspring. It's fun to prod at their ill proportioned chubby bodies for a while at least. So now I may offer my sincere congratulations on the upcoming baby. -Grrrk
Autobahn Accelerator for iTunes
My company, Swarmcast, announced one of our first public releases today. Previously we've been primary selling to content providers, but now we're putting out a user facing free release. If you download our Autobahn Accelerator for iTunes you'll find your purchases from the iTunes music store come down three to ten times faster than they did before. We'll be adding support for lots of other sites (you tube, etc.) in upcoming weeks.
Sadly we've got a MacOS version done, but the installation was deemed too clumsy for the polished Mac experience, so we'll have to wait a few weeks to get that out. Windows only for now (says this Linux user).
Customer Service Call Log
Between telecom troubles, warranty repairs, botched on line orders, and marriage related changes in insurance, mortgage, and bank accounts I've spent a lot of time on the phone with customer service representatives lately. Few issues get resolved in a single call and even fewer without a transfer to another office.
I put together a sheet to keep track of who I spoke to, when, how to get back to them, and what they promised me. Now I grab one whenever I'm about to dial a 1-800 number to talk to the almost-friendly, nearly-helpful people on the other end. Besides the convenience of being able to say "On January 21st at 3pm Janice, CSR number JA5692, told me she'd ship the replacement FedEx overnight," representatives seem on their best behavior when you start out every interaction asking for their name and customer representative number.
View Any Simon Delivers Order
I forwarded a Simon Delivers order receipt email on to a friend, and he was able to view the order without being logged in as me. Turns out that if you have a Simon Delivers account at all they let you view any order. I created a quick web form to let anyone view any order using my account. Here's my favorite order so far:
| Qty | Item Name | Each |
| 1 | Cetaphil Moisturizing Lotion | $10.99 |
| 2 | Coke Diet - 24/12 oz. Cans | $7.49 |
| 2 | Dr Pepper Diet - 24/12 oz. Cans | $7.49 |
| 2 | Hershey's Milk Chocolate Candy Bars - 6 ct. | $3.49 |
| 2 | Life Savers Wintergreen Flavored - Individually Wrapped - Bag | $1.89 |
| 1 | Nabisco Nutter Butter Peanut Butter Sandwich Cookies | $3.79 |
| 1 | Nestea Cool Lemon Iced Tea Fridge Pack - 12/12 oz. Cans | $4.19 |
| 2 | Pepsi - 24/12 oz. Cans | $7.49 |
| 2 | Pepsi 8/12 oz. Bottles | $3.69 |
| 1 | Seven-Up - 12/12 oz. Cans | $4.19 |
| 2 | Seven-Up Diet - 12/12 oz. Cans | $4.19 |
I'm sure fixing this problem is simple as adding whatever the .asp equivalent of this is:
if (currentUser != order.user) {
return;
}
Funny, though.
If you try you own and stumble across any funny ones put the order number in the comments.
Comments
3885593 - Five boxes of cereal and two gallons of milk. -- Nick
2566520 - 15 gallons of bottled water, Milk Bones, and an issue of Minnesota Parent magazine. -- Dan
Alarm System
My favorite book in the Wren Hollow Elementary school library was The Gadget Book by Harvey Weiss. I must have checked it out a hundred times during the second and third grade and tried to build most of the half-practical projects it detailed. The best among them was the burglar alarm. It used wooden blocks, a door hinge, and a strip of metal to make a simple normally-open contact switch. It was the first electrical work I ever did and almost certainly shaped my interests and career path.
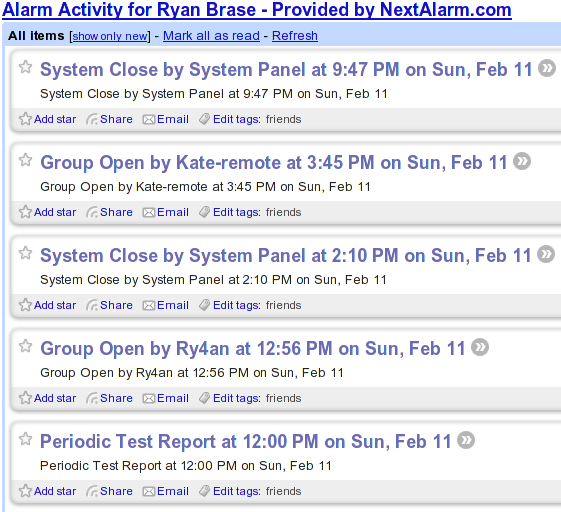
As a winter (read: indoor) project I decided to install a security system. Our system at the office uses DSC components and works well enough, so I used the same. I bought a Power 632 panel on line along with some wired and wireless contact switches, and keypad. The only difficultly during installation was routing the wire for the keypad from upstairs to downstairs where it couldn't be seen. Programming was nothing like modern computer programming. Bits and bytes were entered directly into numbered memory registers by toggling boolean flags and entering hex characters on the keypad. It was oddly fun.
Everything's working quite well. We've got a bevy of contact, motion, and temperature sensors. We can arm/disarm from the keypad or using the wireless remote keys on our key chains. For monitoring I went with next alarm and they even make an RSS feed available (though only through yahoo, so I had to fake the User-Agent: HTTP header);
Trash Can Snorkel
This one's dumb. We've got the same trash can that everyone who shops at Target has. The inner removable pail is handy for keeping spills from pouring out the foot pedal hole, but its air-tight nature creates quite the vacuum when you're trying to pull the bag out.
After ripping the handles off yet another Glad bag trying to get it out of the pail I went to get a drill to poke an air hole in the bottom -- leak proof be damned. Next to the drill I saw a piece of 3/4" plastic tubing, which I ran from the top of the inner pail to the bottom.
|https://ry4an.org/pictures/web/cimg0280|
After a trash day that left the bag handles intact I can report that the hose allows air in without requiring new holes. Future trash pails should have top to bottom air ducts molded into them. Trashcan manufacturers please to be getting on that right now.
Whole House Humidifier
This weekend I put in a Honeywell 360A whole house humidifier. The instructions said it should take an hour, and it only took me four. Nothing went wrong, which what you hope for when a project means cutting holes in your duct work, tapping into your water, and some wiring. Now when we wake up our throats don't hurt.


Comments
Update: If you don't tighten down the compression fittings on the water supply line it will let go and you'll drain water into the floor drain all night. d'oh
From a concerned internet'er Get rid of that saddle valve at your earliest convenience, those things a prone to leaking or letting go. Have someone put in a tap on the line with a proper cutoff with a 1/4"FIP. Same connector you would use for an icemaker. To be real safe after you do that you can buy a braided steel icemaker line that will connect inbetween the cutoff and the humidifier, so no compression connectors anymore either.
Home Repair and Misc.
When I don't post here in a while it either means I'm not building anything new or that I'm too busy to write about what I am doing. This time it's the later. Not that any of it's been exciting, but almost all of it involved using a saw, which totally counts.
Gwin, our eldest cat, has always kicked toys into the basement sump for the joy of watching humans pick them out later. Milo, on the other hand, likes running into the muddy sump and then running up stairs. To keep the cats and their toys out I built a little wooden frame to fit and covered it with chicken wire. It's ugly but functional.
|https://ry4an.org/pictures/web/Sump|
At some point during Monday night's storm a 20' branch fell from the sky and broke our fence gate. Neither of us woke up. Sometimes I park my car right where it landed, and I'm glad Monday wasn't one of those times. Repair was just a matter of replacing a few pickets and fixing the latch. The latch has never worked well and still doesn't, but it's slightly better, which I keep telling Kate counts as fixing it.
|https://ry4an.org/pictures/web/Gate|
Meager construction efforts aside I've been working on some big things at work and on our [http://kateandry4an.org/gallery/invitation wedding invitations], which we hope to mail in the next week or two.
Meager Home Improvements
After moving into the house I started a series of small home improvement tasks. Some of them have genuine safety reasons but many happened only because changing things demonstrates residence. Here's an incomplete list of things I've done:
- added a ceiling fan to the bedroom
- rewired the doorbell with modern wire so it doesn't ring everytime you walk past the dining room heat register
- added shelving, a phone jack and power outlets to create a server corner
- added appliance-grade outlets behind the stove and fridge (rather than the ungrounded lamp-grade extension cords running through holes in the floor they previously had)
- added a motion light to the break-in-ariffic back yard
- cleaned out the gutters (I knew there's a reason I got that condo)
- replaced the rotting wiring for the basement lighting
|https://ry4an.org/pictures/web/datacenter| |https://ry4an.org/pictures/web/motionlight|
Display Google Calendars with PHP iCalendar
Google has a new calendar service, and it's great. I really try to avoid hosted data solutions, but this one's just too good to pass up. My one gripe is that there's no easy way for non google calendar users to view the calendars. They're available live as both ical and rss/xml files, but the average home web user doesn't know what to do with either of those.
There are plenty of services out there that will display an ical file as a web page, but none of them I tested rendered the google ical output well, and all of them were packed with ads. Previously, I'd used software called phpicalendar to display ical files created by my old calendaring solution on the web, so I started there. It didn't parse the google output well either. However, with a little tweaking (see the patch in the zip file below) and some Apache trickery (see the README in the zip file) I can now get good phpicalendar output from google.
google-calendar-phpicalendar-2.22.zip
Update: Looks like now google offers a good way to do this.
Comments
Hey man I really want to get my php iCalendar working with my new Google Calendar as you have, but my server is not a Linux box, so I don't have a good way to patch the diff file you included in the zip. I was wondering if you would be willing to upload the actual files that you changed, or would you be willing to email them to me. I would really appreciate it.
Hrm, not to be unhelpful, but if you read the patch file you'll see I just commented out one block and added a simple if test somewhere else. It should be very easy to do by hand on the two files. The unified diff format is nice in that it's quite human readable despite being ready for machine processing. -- Ry4an
I'm not familiar with php icalendar, but (stupid question...) if using your work around, and I keep making new events in the google calendar, will they show up in the icalendar, or will some kind of cron job be required? (maybe I should just use the icalendar... but the google site is so seductive....) --Rebecca, cookieshouse.com
Yes, my phpicalendar hack does a live display of the google data. One could use phpicalendar all by itself, but I like the invites, access controls, and UI from google calendar well enough that I though it was worth trying to have phpicalendar do a live display of data I keep in google calendar. -- Ry4an
I was all excited to work on this little project. Then I realized I don't have the ability to apply patches (or if I do, I haven't a clue how to). Thanks for sharing though, it looks super cool on your site! --Rebecca, cookieshouse.com
I could not get your method to work so I had to rework the ical_parser.php. I recreated the $cal_filelist array with my google calendar urls. Then so the names of the calendars were not "basic" I created another array called $cal_names. Here maybe some source code will make this more clear. At about line 102 of ical_parser.php
$cal_filelist = array ("http://calendar url 1", "http://calendar url 2");
$cal_names = array ("Calendar Name 1","Calendar Name 2");
$counter = 0;
foreach ($cal_filelist as $cal_key=>$filename) {
// Find the real name of the calendar.
//$actual_calname = getCalendarName($filename); original code commented out
$actual_calname = $cal_names[$counter];
$counter++;
}
-- Psycho Whale
That's a more general solution than my quick hack. You might want to submit your code changes back to the phpicalendar project using their patch tracker. I'm sure they're getting all sorts of "support google calendar" requests and yours is a good step toward that. -- Ry4an
I applied your patch... no problem. But when I did the .htaccess edit, it would not redirect the .ics file to the google calendar. I then edited the config.inc.php to allow webcal's and added the exact patch of the .ics (which would be redirected) in the "$list_webcals[] = *;" area. No dice. It would then give me an error (which is strange since the file actually existed in that spot). Any idea what I'm doing wrong? Do I need to edit the "$default_path" in the config.inc.php to show the patch to the redirected .ics file also? I'd love to get this thing to work but doesn't seem to be happening. Tried Pycho Whale's solution also but that worked even less. Not sure if he was editing the ical_parser.php before or after your patch or if that even was relevent. Lot's a questions. Any help? -- RSmith423
If the .htacces file is ignoring your Redirect line it's because your httpd.conf file isn't set to allow Redirect lines in .htaccess files. You can either edit httpd.conf to allow Redirect lines in .htaccess files or you can just put the Redirect line directly into the httpd.conf file. Instructions for both can be found in the Apache online help. -- Ry4an
I noticed that recurring events don't display correctly. If you have a recurring event the start time and end time is always the same.
Here is my hack to PHP iCalendar to make it work:
in ical_parser.php:
my code:
ereg('^PT([0-9]+)S', $data, $duration);
$the_duration = $duration[1];
replaces this original code:
ereg ('^P([0-9]{1,2}[W])?([0-9]{1,2}[D])?([T]{0,1})?([0-9]{1,2}[H])?\([0-9]{1,2}[M])?([0-9]{1,2}[S])?', $data, $duration);
$weeks = str_replace('W', '', $duration[1]);
$days = str_replace('D', '', $duration[2]);
$hours = str_replace('H', '', $duration[4]);
$minutes = str_replace('M', '', $duration[5]);
$seconds = str_replace('S', '', $duration[6]);
$the_duration = ($weeks * 60 * 60 * 24 * 7) + ($days * 60 * 60 * 2\4) + ($hours * 60 * 60) + ($minutes * 60) + ($seconds);
Apparently Google uses seconds to specify the duration of the event, but PHP iCalendar expects the duration in hour minute second format.
Thanks for the patch!
-Charles
The only thing I had to do to get GoogleCalendar to work was the following:
phpicalendar/config.inc.php: $allow_webcals = 'yes'; phpicalendar/config.inc.php: $timezone = 'Europe/Paris'; php.ini: allow_url_fopen = On
And it worked right out of the box ...*
http:// YOUR-SITE /phpicalendar/month.php?cal=http://www.google.com/calendar/ical/ YOUR-GMAIL /public/basic&getdate=20060518
Thomas.
Excellent, maybe they've updated. I kept having it refuse to display any webcal URL that didn't end in '.ics', pehaps that's been fixed. Also, I found I needed to add some link text to the blank free/busy view entries for them to be clickable, but that would only be required if you use the free/busy (rather than full detail) view gcalendar provides. --* Ry4an
Fixing the Roomba Circle Dance
My Roomba had been on the fritz lately. When I powered it on it went forward a few inches and then started backing up in a tight circle. I figured it was a dirty sensor, but I cleaned everything I could see and had no luck.
My coworker Brandon pointed me to the Circle Dance website, which explains how a dirty internal sensor can cause just that problem. I've got an older Roomba, but the wheel assembly seemed the same. The site has great instructions and photos showing how one can fix the problem. They do, however, go through incredible contortions, including removing 10 screws and a hard to replace panel, just to remove a single screw.
I found I could skip all that by drilling a small hole in the fender rather than removing it. Given that replacing the fender is so difficult the original site recommends not bothering, I think a hole is an acceptable level of resulting cosmetic defect.
This image shows just where the hole was made:

...and now the Roomba works great again.
Improving Nick Tracking using String Similarity
Years back I wrote an IRC nick tracking script. It's served me well since then, but it has one major annoyance. When people changed their name slightly it would remember that name change, even though the old/new mapping didn't contain any real identity change information.
For example, when Gabe_ became Gabe it would display every message from him as <Gabe_(Gabe)>. That doesn't tell me anything interesting about who Gabe is.
I decided to tweak the tracker to ignore small changes in names. Computers don't think in terms like small they need a way to quantify difference and then see if it exceeds a specified threshold. Fortunately, lots of people have worked on just that problem -- mostly so that spell checkers can present you with a list that's close to the non-word you typed.
When I've worked with close enough strings in the past I've used the Levenshtein_distance as implemented in the String::Approx module or the ancient Soundex algorithm. This time, however, I tried out the String::Trigram module as written by Tarek Ahmed, which implements the method proposed by Angell in this paper. Here's an explanation from String::Trigram's README file:
This consists of splitting some string into triples of
characters and comparing those to the trigrams of some other string. For
example the string kangaroo has the trigrams "{kan ang nga gar aro
roo}". A wrongly typed kanagaroo has the trigrams "{kan ana nag aga gar
aro roo}". To compute the similarity we divide the number of matching
trigrams (tokens not types) by the number of all trigrams (types not
tokens). For our example this means dividing 4 / 9 resulting in 0.44.
Thus far, at a 50% match threshold it's never failed to detect a real change or ignore a minor-change, and if it does I should just be able to notch the match-threshold higher or lower. Great stuff.
The modified script can be viewed here and downloaded here.
Comments
If you wanted to only track nick changes in certain channels you'd add code line this at line 86:
return unless grep /^$chan$/, qw(#channelone #channeltwo #channel3);
I've modified 1.1 with a new /function, trackchan, that allows one to manage a list of channels where they want nick tracking to take place. If the list is empty, tracking will be done in all channels. The following is a unified diff.
What it doesn't do:
- Check to make sure that the channel you're passing in actually conforms to any standard channel naming conventions.
- Check to see if the channel already exists in the list before trying to remove it (though thanks to it just being a simple grep, no errors is returned in any case).
- Check to see if you're adding a duplicate channel to the list (feel free, it doesn't affect the functionality one bit).
- Have an option for printing the channel list. I think I will modify it to just print the channel list in addition to the usage if /trackchan is called with no arguments.
-- Gabe
--- nick-track.pl.orig Thu Dec 22 10:37:34 2005
+++ nick-track.pl.trackchan Thu Dec 22 14:50:30 2005
@@ -22,7 +22,7 @@
use Irssi;
use strict;
use String::Trigram;
-use vars qw($VERSION %IRSSI %MAP);
+use vars qw($VERSION %IRSSI %MAP @CHANNELS);
$VERSION = "1.1";
%IRSSI = (
@@ -47,6 +47,7 @@
'Asrael' => 'Sammi',
'Cordelia' => 'Sammi',
);
+@CHANNELS = qw();
sub call_cmd {
my ($data, $server, $witem) = @_;
@@ -84,6 +85,13 @@
my ($chan, $nick_rec, $old_nick) = @_;
my $nick = $nick_rec->{'nick'};
+ # If channel list is empty, track for all channels.
+ # If channel list is non-empty, track only for channels in list.
+ my $channels = @CHANNELS;
+ if ($channels > 0) {
+ return unless grep /^$chan$/, @CHANNELS;
+ }
+
if (defined $MAP{$old_nick}) { # if a previous mappings exists
if (String::Trigram::compare($nick, $MAP{$old_nick},
warp => 1.8,
@@ -101,6 +109,34 @@
}
}
}
+
+sub trackchan_cmd {
+ my ($data, $server, $witem) = @_;
+ my ($cmd, $channel) = split ' ', $data;
+ my @cmds = qw(add del);
+
+ unless (defined $cmd && defined $channel && map($cmd, @cmds)) {
+ print "Usage: /trackchan [add|del] #channel";
+ return;
+ }
+
+ if ($cmd eq 'add') {
+ push @CHANNELS, $channel;
+ print "$channel added to channel list";
+ }
+
+ if ($cmd eq 'del') {
+ @CHANNELS = grep(!/^$channel$/, @CHANNELS);
+ print "$channel removed from channel list";
+ }
+
+ print "Current channel list:";
+ foreach my $channel (@CHANNELS) {
+ print " $channel";
+ }
+}
+
+Irssi::command_bind trackchan => \&trackchan_cmd;
Irssi::signal_add("message public", \&rewrite);
Irssi::signal_add("nicklist changed", \&nick_change);
Thanks, Dopp, great stuff! -- Ry4an
Linux on the Dell X1
Yesterday I got the warranty replacement machine for my (company's) Dell X300 laptop. Dell mailed me an X1, which seems a nice enough machine. It meets my firm criteria: under 3 lbs and thinner than an inch. If Apple would hit those numbers I'd be there in a second.
Unfortunately, it looks like getting Linux on to this thing is going to be a pain. Emperor Linux will sell an X1 with Linux pre-installed, but they want $450 to take the X1 I already "own" and put Linux on to it. If they're not able to simply mirror a debugged installation over, that says a lot about their volume. I value my time pretty highly, but $450 for a software install seems extreme.
Fortunately there are plenty of pages detailing how to get Linux running on the X1. I'll muddle through the process and attach my notes as comments.
Comments
I've found that to boot Knoppix using the external optical drive I need to use this boot time invocation:
knoppix fromhd=/dev/uba
Now to try qtparted to squish down the NTFS windows partition to something reasonable.
Using ntfsresize and fdisk I was able to squish the windows install down to 10GiB. Now I'm just waiting for my fedora core 4 DVD to arrive for install.
Fedora Core 4 installed from the DVD without a hitch. I had to download the ipw2200 firmware RPM to make the wireless work. The 855resolution utility as invoked from rc.local and tweaked in xorg.conf got the resolution notched up. Next up... ion.
Email Sub-Address Spam Frequency
My email server is configured such that email to ry4an-anything@ry4an.org gets correctly delivered to me. The dash and whatever is after it are retained but ignored completely.
When I give an email address to a company, say Northwest Airlines,I'll give them an email address that shows to whom it was given, say ry4an``-nwa``@ry4an.org. By doing this I'm able to check which companies are giving/selling/leaking my email address to spammers. Some of the leaks are surprising -- just a few weeks after giving out ry4an-philmont for the first time, giving it to the Boy Scouts, I started getting porn spam on it. When I called to let them know about the leak they assured me it was impossible.
Last month I decided to save all of my inbound spam and run some totals to see which sub-addresses got the most spam. Here are the counts:
- 6427 total spam messages to ry4an.org in 34 days
- 679 spam messages to plain ry4an*@*ry4an.org
- the 10 most spammed sub-addresses were
| Received | Address | Given to |
| 2542 | ry4an-slashdot | Posted to http://slashdot.org |
| 252 | ry4an-dip | Used in the Diplomacy community |
| 159 | ry4an-resume | On my resume |
| 141 | ry4an-yahoo | Given to yahoo.com |
| 125 | ry4an-cnet | Byline for some articles I wrote |
| 98 | ry4an-oldenburg | Defunct Oldenburg project |
| 88 | ry4an-poker | Used at https://ry4an.org/poker/ |
| 84 | ry4an-tclug | Given to the Twin Cities Linux Users' Group |
| 62 | ry4an-dns | Used for all my domain registrations |
| 44 | ry4an-keysigning | Posted at https://ry4an.org/keysigning/ |
So it looks like the worst offenders aren't comanies to whom I've given my email address, but rather letting them get posted to the internet for automated crawlers to harvest.
Gmail users: You can do the same thing using the plus sign.
Comments
Yeah, the one I gave to United actually garners me the most spam. I emailed them to complain but was brushed off relatively quickly. -- Anonymous
Using Mutt to Automate Mailman Message Rejections
Since this post I've upgraded my mailman installation to a newer version, which allows me to automatically reject messages from non-subscribers without having to resort to external scripting.
However, some of the mailing lists I run are subscribed to by a significant number of members who can't be counted on to post from the email address with which they subscribed, or indeed to even understand what that means. For those lists a policy that automatically rejects messages from non-members is just too draconion. Unfortunately, that means the few spam messages a day from non-members which make it past my filters but would normally be automatically rejected due to their non-member origins have be manually discarded so that I can approve the few non-member messages per month that really do belong on the list.
Relying on mailman's email control interface (as differentiated from its web control interface) I was able to craft the following mutt macro to make the rejecting of undesirable non-member messages a single keystroke affair:
macro index X ":set editor=touch^Mv/confirm^Mryqd:set editor=\"vim -c 'set nocindent' -c 'set textwidth=72' -c '/^$/+1' -c 'nohlsearch'\"^M"
When the 'X' key is pressed the message editor is set to the UNIX 'touch' command which represents absolute minimal message editing. The rest of the macro replies to the confirmation subpart of the mailman message, which indicates rejection to mailman's email control interface. After the reply is sent the message editor is set back to it's usual value (vim).
Halloween 2005
Last weekend Bridget, Joe, and I threw our annual Halloween party. It was well attended and everyone seemed to have a good time. It peaked around midnight with a good 50 people inside and out, which is about the same as last year.
This year we did a little more with the decor including the building of a coffin cut-out and a few corpses. The walls got covered with cheesy off the shelf decorations that drew more praise than anything else -- go figure.

Photos are starting to get posted by various attendees, and I'll post them here as more appear. Not all photos in all sets are from our party, but a goodly fraction are:
- http://www.livejournal.com/users/soundingsea/184134.html
- http://www.flickr.com/photos/autodidact/sets/1248794/
- http://trogdor.dopp.net/Halloween%202005/
- http://photos.megancarney.com/Albums/2005-10-29%20Halloween/
Thanks to all who attended,
A Cheap and Easy Sidebar
I hacked the MonthCalendar macro for moin moin to include some javascript which includes a sidebar built from a RSS feed. The javascript and back-end Rebol were written by p3k.org. The RSS feed is produced from (a subset of) my links at del.icio.us. All in all a quick, easy addition, requiring just a little Python twiddling.
Wow, this post contains almost no nouns a normal person would recognize.
Comments
Hrm, the side bar stopped working because the http://p3k.org site hasn't been responding for at least 24 hours. I wonder if/when it will come back. If anyone notices it's returned let me know and I'll re-enable the side bar.
That sort of thing is exactly why I don't like relying on external web services be they flickr, gmail, del.icio.us, or whatever. I know in theory google and yahoo can keep those services running with 100% availability, and that they don't want the PR hit that elmininating them would cause, but still if you're not paying someone to store you're data you shouldn't expect it to still be there tomorrow.
The p3k site is back up, but I switched over to using del.icio.us directly for the rendering. I recall they used to request that you not put anything on your webpages that hits their site for every page view, but they seem to be encouraging it now. Their link rolling seems to work that way, anyway (and works quite well, at that).
Isle Royal GPS Data
Earlier this month some friends and I hiked across Isle Royale in lake Superior. Joe kept his GPS running and produced good track points in an odd export format from his Mac software called "Topo". I created a quick conversion script to produce this GPS format data which can be used with the GPS visualizer website to produce images like this:
Vodka Fruit Infusion
A few months back Kate Bauer and I hosted a BBQ at her place. I wanted to try putting together a fruit and vodka infusion of the sort I'd previously seen at bars.
Kate bought a bunch of fresh fruit and I picked up the vodka (Svedka, the best vodka for the dollar, and damn near the best at any price). We used the same glass container from Pier One I purchased to house pickled eggs for my Moe the bartender Halloween costume a few years back. The infusion came out great, but we learned a few things along the way:
- Pineapple is a great filler
- Strawberries lose their color and look pale and sad
- Kiwi sticks to the glass
- Decant some into a pitcher for easy pouring
Initially we set up a complicated siphon and valve system which worked well enough, but scared people away. Once we decanted the vodka off the drink really went quickly.
As one would expect the final product tasted like candy, but had the potency of hard liquor -- yikes.

Shades of Coke Blind Taste Test
On Sunday Kate Bauer and I ran and participated in a double blind random taste test of the various shades of Coca-Cola. Into numbered glasses Kate poured the samples from bottles whose labels I'd replaced with lettered labels. The samples we included were:
- Coke
- Diet Coke
- Diet Coke with Splenda
- Coke C2 (already hard to find!)
- Coke Zero
Kate was 3 for 5 with only Coke and C2 transposed. I got only one of them right (everyone knows the gasoline flavor of Diet Coke). From this we can conclude that either Kate's got a much better palate than I do or that she drinks a lot of Coke when I'm not looking.

MTN Televised Scrabble Archive
I've been hooked on MTN's televised scrabble since Kate Bauer and I stumbled across it a few weeks back. The only on-line mention I can find of it is an old review in a student paper.
I'm thinking of getting a group of folks together to play as a team semi-regularly, but while that's getting setup I decided to start archiving the games, because that's the sort of thing I do, I guess.
I started out by looking to see if there already was a standard scrabble game notation. There are a few, but none of them are particularly well thought out. The most commons seems to be the log2 format. It's human readable, but pretty fiddly syntax wise.
Last weeks game as a log2 file starts like this:
Hamil Mpls 8h CARP +16 16 MIXIWOD i7 WAX +25 25 h8 COPE +17 33 IIMODTL 11e MODEL +16 41 9g FOX +17 50 IITEYTG 10d GEY +28 69
In addition to creating a log2 file for the game, I created a first cut at an on-line HTML visualization as found here: https://ry4an.org/scrabble/games/2005-06-21/ The image on that page:

was created with the help of the board display tool by Graham Toal.
Once I get that page into a format I like, I'll probably create a CGI that converts log2 files to HTML visualizations on the fly. I, however, definitely don't have time for something like that now.
Comments
I think this idea is really cool. -Hamil
Campfire Frozen Pizza
Last weekend I was camping and the person buying the food bought frozen pizzas. I couldn't think of any good way to cook them until I saw we had some aluminum foil. We defrosted the pizzas and cut them into slices. Slices were places face-to-face, wrapped in two layers of tin foil, and then tossed into the coals of our fire. After ten minutes or so they were fished out, and they'd turned into perfectly palatable pizza-pocket-alikes. It's not good camping food, but its better than raw frozen pizza.
Comments
but was it freschetta rising crust pizza? that stuff is good. especially with pre-packaged caesar salad.
CVS Commit Blocking
When editing source files checked out from CVS I sometimes want to prevent them from going back in to source control without further edits. Until now I've just used // FIXME comments and have tried to remember to grep for FIXMEs before committing the files back.
Problem is others use FIXME comments, and sometimes I forget to grep. So I've tweaked our CVSROOT files to prevent custom FIXME tags from going in to source control.
I appended this line to CVSROOT/commitinfo:
ALL $CVSROOT/CVSROOT/checkforry4an
Added this line to CVSROOT/checkoutlist:
checkforry4an Tell Ry4an he broke something with checkforry4an
and crated a file named CVSROOT/checkforry4an containing:
#!/bin/sh
BASE=$1
shift
for thefile in "$@" ; do
if echo $thefile | grep -v Foreign | grep -q '.java$' ; then
if grep -s -q 'FIXME RY4AN' $thefile ; then
echo found a FIXME RY4AN in $thefile
exit 1
fi
fi
done
Now when I put a // FIXME RY4AN comment into a source file commits break until I remove it.
Garble To GPX Track Conversion
For years I've been using garble to pull track and way point data off of my Garmin eTrex GPS. Unfortunately it produces data in a completely non-standard format. In the past I've written a little custom software to turn the garble data into maps.
Now I'm using http://gpsvisualizer.com to produce much nicer maps, but it takes data in the superior GPX format. The GPSBabel software will pull way point data off of Garmin GPSs and puts them into GPX, but it doesn't handle tracks.
So, I needed something that took garble output like:
45.222774, -92.767997 / Sun Apr 10 18:57:32 2005
and turned it into GPX statements like:
<trkpt lat="45.222774" lon="-92.767997"><time>2005-04-10T18:57:32Z</time></trkpt>
this Perl snippet I wrote:
#!/bin/perl -w
use strict;
use Date::Parse;
use Date::Format;
while (<>) {
chomp;
unless (/(\S+), (\S+) \/ (.*)/) {
print STDERR "Unparseable line: '$_'\n";
next;
}
my $when = str2time($3);
my $time = time2str('%Y-%m-%dT%H:%M:%SZ', $when);
print qq|<trkpt lat="$1" lon="$2"><time>$time</time></trkpt>\n|;
}
does the job.
Adopt a Vegetarian
I was just digging through some old files, and I came across my first web pages. They were hand written HTML done in late 1995. Among the worst of them design-wise was my 'Adopt a Vegetarian' page. It was a joke started in October 1995 wherein non-vegetarians would "adopt" vegetarians and agree to eat twice as much meat, so as to balance the vegetarian out.
The Adopt a Vegetarian website was up before most of the world had even heard of the web, and certainly before folks learned not to take anything on-line too seriously. The volume of vitriolic hate mail I got was amazing. I wish I'd have saved them. The site existed during the period when the mainstream press was writing a lot of "gee whiz, look at this crazy website" articles. I ended up getting written about in a few different publications including Der Spiegel (wikipedia), which I've got clipped and stored somewhere.
Anyway, I re-rendered the site for the first time in ages, and here's a screen shot to that monument of bad taste in both design and humor.
Approval Voting for the ACM
Approval voting is an alternate voting system that has many benefits as compared to Instant Run-Off Voting. For years I've been running the on-line officer elections for the local campus chapter of the Association of Computing Machinery. Last year I talked them into switching to approval voting (even though it probably violates their charter), and it worked really well. Their elections have kicked off again, and once again I'm hosting them and using my voting script.
SwarmStream Article on the O'Reilly Network
I wrote an article that got posted on the O'Reilly Network. It sounds a little more huckster-ish than I'd like, but the tech does get explained pretty well. There's a link to the new beta 2 release of SwarmStream Public Edition at the bottom of the article.
Detecting Recently Used Words On the Fly
When writing I frequently find myself searching backward, either visually or using a reverse-find, to see if I've previously used the word that I've just used. Some words, say furthermore for example, just can't show up more than once per paragraph or two without looking overused.
I was thinking that if my editor/word-processor had a feature wherein all instances of the word I just typed were briefly highlighted it would allow me to notice awkward repeats without having to actively watch for them. Nothing terribly intrusive, mind you, but just a quick flicker of highlight while I type.
A little time spent figuring out key bindings in vim, my editor of choice, left me with this ugly looking command:
inoremap <space> <esc>"zyiw:let @/=@z<cr>`.a<space>
As a proof-of-concept, it works pretty much exactly how I described, though it breaks down a bit around punctuation and double spaces. I'm sure someone with stronger vim-fu could iron out the kinks, but it's good enough for me for now. Here's a mini-screenshot of the highlighting in action.
I'm sure the makers of real word processors, like open office, could add such a feature without much work, but maybe no one but me would ever use it.
Obscuring MoinMoin Wiki Referrers
When you click on a link in your browser to go to a new web page your browser sends along a Referrer: header, which tells the owner of the site that's been linked to the URL of the site where the link was found. It's a nice little feature that helps website creators know who is linking to them. Referrer headers are easily faked or disabled, but in general most people don't bother, because there's generally no harm in telling a website owner who told you about their site.
However, there are cases where you don't want the owner of the link target to know who has linked to them. We've run into one of these where I work because one of our internal websites is a wiki. One feature of wikis is that the URLs tend to be very descriptive. Pages leaving addresses like http://wiki.internal/ProspectivePartners/ in the Referrer: header might give away more information than we want showing up in someone else's logs.
The usual way to muffle the outbound referrer information from the linking website is to route the user's browser through a redirect. I installed a simple redirect script and figured out I could get MoinMoin, our wiki software of choice, to route all external links through it by inserting this into the moin_config.py file:
url_mappings = {
'http://': 'http://internal/redirect/?http://',
'https://': 'http://interal/redirect/?https://'
}
Now the targets of the links in our internal wiki only see '-' in their referrer logs, and no code changes were necessary.
Comments
I'm working on installing a some what sensitive wiki, so this is interesting.
How does the redirect script remove the referer, though? I couldn't figure that out from the script.
It just does due to the nature of the Referrer: header. When going a GET a browser provides the name of the page where the clicked link was found. When a link on page A points to a redirection script, B, then the browser tells B that the referrer was A. Then the redirect script, B, tells the browser to go to page C -- redirects it. When the browser goes to page C, the real target page, it doesn't send a Referrer: header because it's not following a link -- it's following a redirect. So the site owner of C never sees page A in the redirect logs. S/he doesn't see the address of B in those logs either, because browsers just don't send a Referrer header: at all on redirects. -- Ry4an
There was a little more talk about this on the moin moin general mailing list, including my proposal for adding redirect-driven masking as a configurable moin option. -- Ry4an
SwarmStream Public Edition
My latest project for Onion Networks has just been released: it's a first beta release of SwarmStream Public Edition, a completely free Java protocol handler plug-in that transparently augments any HTTP data transfer with caching, automatic fail-over, automatic resume, and wide-area file transfer acceleration.
SwarmStream Public Edition is a scaled-down version of our commercially-licensable SwarmStream SDK. Both systems are designed to provide networked applications with high levels of reliability and performance by combining commodity servers and cheap bandwidth with intelligent networking software.
Using SwarmStream Public Edition couldn't be easier, you just set a property that adds its package as a Java protocol handler like so:
java -Djava.protocol.handler.pkgs=com.onionnetworks.sspe.protocol you.main.Class
So, if you're doing any sort of HTTP data transfer in your Java application, there is no reason not to download SSPE and try it out with your application. There are no code changes required at all.
Better Random Subject Lines
Earlier I talked about generating random Subject lines for emails. I settled on something that looked like Subject: Your email (1024) . Those were fine, but got dull quickly. By switching the procmail rules to look like:
:0 fhw * ^Subject:[\ ]*$ |formail -i "Subject: RANDOM: $(fortune -n 65 -s | perl -pe 's/\s+/ /g')" :0 fhw * !^Subject: |formail -i "Subject: RANDOM: $(fortune -n 65 -s | perl -pe 's/\s+/ /g')"
I'm now able to get random subject lines with a little more meat to them. They come out looking like: RANDOM: The coast was clear. -- Lope de Vega
However, given that the default fortune data files only provide 3371 sayings that are 65 characters or under the Birthday_paradox will cause a subject collision a lot sooner than with the 2:superscript:15 possible subject lines I had before.
Update: It's been a few weeks since I've had this in place and my principle subject-less correspondent has noticed how eerily often the random subject lines match the topic of the email.
Jetty with Large File Support
Jetty is a great Java servlet container and web server. It's fully embeddable and at OnionNetworks we've used it in many of our products. It, however, has the same 2GiB file size limit that a lot of software does. This limit comes from using a 32 bit wide value to store file size yeilding a 4GiB (unsigned) or 2GiB (signed) maximum, and represents a real design gaff on the part of the developers.
Here at OnionNetworks we needed that limit eliminated so last year I twiddled the fields and modified the accessors wherever necessary. After initially offering a fix and eventually posting the fix it looks like Greg is getting ready to include it thanks in part to external pressure. Now if only Sun would fix the root of the problem.
Adding a Subject with Procmail
Lately I've been corresponding a great deal with someone who doesn't elect to use the Subject: line in emails. When responding to this emails my mail application, mutt, uses the Subject line: re: your mail. Mutt also groups conversations into threads using (among other things) the Subject line. So every reply to every person who has sent a message with a blank subject line gets grouped into a single thread when they, in fact, have nothing to do with one another.
I decided to create Subject lines for incoming messages without them on the fly using the standard procmail tool. This pair of recipes does the trick:
:0 fhw * ^Subject:[\ ]*$ |formail -i "Subject: Your email ($$)" :0 fhw * !^Subject: |formail -i "Subject: Your email ($$)"
The $$ gets turned into a low number (the process id actually) which is unique enough to keep threads separate. The resulting Subject lines look like: Subject: Your email (1024) } and have been working quite well.
There's probably a way to use a single recipe to catch both cases (blank Subject and no Subject), but I hate procmail's almost egrep and just settled on this.
Comments
Test comment.
The girl who refuses to use subject lines is leaving a comment. -- Kate Bauer
I updated this idea in a later entry. -- Ry4an
2004 Email Response Patterns
Back in 2003 I started tracking some numbers on my email use patterns, especially related to replies. I ran those old scripts on my 2004 mail and the numbers look pretty similar:
- Of the 3236 emails I sent during 2004, 2094 of them were replies
- My five most common response times in minutes were:
- ten minutes: 40 times
- thireen minutes: 36 times
- sixteen minutes: 36 times
- twelve minutes: 35 times
- eleven minutes: 33 times
- My mean response times was 22.36 minutes
- My longest response time was 58.4 days.
The only really meaningful number there is the median response time and comparing it to 2003, I'm a lot faster in general.
My email volume by year is:
| Year | Emails Sent |
|---|---|
| 2000 | 1920 |
| 2001 | 1799 |
| 2002 | 1920 |
| 2003 | 3136 |
| 2004 | 3236 |
Looking at that table it's pretty easy to tell when I started working from home again.
Here's the histogram for 2004:
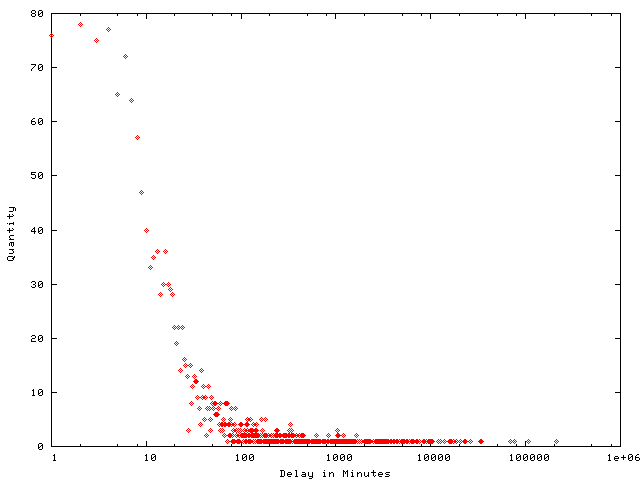
New UnBlog System
I've switched from a mailing list driven system to a wiki based one for this UnBlog. It's less weird than the mailing list setup was, but it's not exactly moveable type either. It offers RSS feeds and subscriptions, though through entirely different mechanisms than the list did. I think I've moved everything over well enough that there are no dead links into the old space. I ended up using my WikiChump thing modified to handle attachments and create comment pages to populate the data.
Brute Forcing My Own Password
I try to maintain good password practices -- total random gibberish, never use the same password for two things, change them monthly --, and the EBP lite from http://mandylionlabs.com/ certainly helps.
Last night, at about 3am I was doing my monthly password change and somehow I typed one password wrong in exactly the same way three times. Today when I tried to add my ssh private key it just wouldn't unlock. I tried the "right" password 10 or so times and no luck. I then started trying slight variants on the password: fingers shifted, missed shift key, similar looking characters, etc. After 30 or so of those tries with no luck it was time to script.
Ten minutes later I had a list of 27,648 (4 * 3 * 4 * 3 * 3 * 4 * 4 * 4) possibilities and ten seconds later permutation number 2308 proved correct. Whew. One would think this would teach me to be more careful, but really it's shown me that so long as one has strong script-fu close-enough is good-enough.
Time For Another Key Signing
It's time once again for that marriage of mathematics and paranoia that is a cryptographic key signing. I'm organizing another for Thursday, January 20th, 2005. Details can be found at: https://ry4an.org/keysigning/ Results from my last key signing can be found at: http://ry4an.org/keysigning/visualize/
If all that's gibberish to you, check you my much better explanation last time I did one of these: https://ry4an.org/unblog/msg00026.html
Thanks once again to the ACM for letting us use their room.
Comments
glad to see a new posting. i was getting concerned your new non-geek pursuits were interfering with your true purpose. -- Kate Bauer
Dead Pool Update
I've got the entries and current scores posted for the Dead Pool at http://sarinity.com/deadpool/ . Thanks to those who entered. I was planning on hitting everyone up to join at the Halloween party, but then I got distracted and forgot. O'well six people, two of whom already have points, is good enough.
Best of luck to the entrants,
AntFlow 1.0rc1 Released
I code for a hobby and a profession, but usually it's only the hobby stuff I can release here. However I'm happy to say and proud to announce that Onion Networks, my employer, has okay-ed the release of AntFlow, a tool I largely wrote.
AntFlow adds hot folder triggers and workflow functionality to the ever popular Ant build tool. It's a great fit and a right good bit of code, so check it out at http://antflow.onionnetworks.com/ .
A Clockwork Orange Costume
My Halloween costume this year came out pretty well. I went as Alex from Kubrick's A Clockwork Orange during his brainwashing. I made the head piece from scrap metal, some syringes, galvanized steel wire, rubber tubing, and a lot of rivets. The actual actor was temporarily blinded during the filming of that scene, but I went less hard-core on the eye restraints and the only after effects I've got are some bruising and puffiness. All in all better than I was hoping for. See the attached image for a photo. Thanks to the Kromhout clan for the photo.

Dead Pool
I've decided to run a dead pool this year. You can sign up at http://sarinity.com/deadpool/ by guessing 10 famous persons who you think might die during the next calendar year. The younger they are the more points you get, and the highest point total wins. Remember, it's not any more morbid than fantasy football is athletic.
Mail To Wiki Gateway
I wanted a way to quickly append text to Moin Moin wikis. I wrote a Perl script to do just that. It relies on the email address suffix features available in most modern MTAs to get the page name.
Once the procmail recipe included in the accompanying procmail.rc file is in place for the user 'wiki' email sent to wiki-TextHere@somewhere.com will be appended to the TextHere wiki page.
I cheaped out on the formatting and just put the text inside literal/pre blocksblocks. The subject line and from header are retained and displayed.
By default the posts are done under no user, but the included makecookie.pl can be used to create a cookie file that the script will use to persist a wiki login (I tend to use EmailGateway).
It looks like there's been some updating and porting discussion of this script at ScriptMarket/EmailToWikiGateway
Diplomacy Tutorial
My all time favorite board game is called Diplomacy. It's got the tactical simplicity of chess mixed with the social aspects of poker. It's been popular in quite a few white houses -- reportedly the Kennedys played ferociously.
Unfortunately, it can be a difficult game to learn. Not because the rules are complex -- they're not, but only because there aren't a lot of good presentations of the rules. Oral descriptions quickly devolve into edge cases and exceptions, the printed rules look like they were written by lawyers, and just looking at the game board gives one the totally wrong impression that Diplomacy is like Risk or the hateful Axis and Allies.
A few years back I decided that a simple introduction to the rules was lacking, so I set out to create one. It's available at https://ry4an.org/diptutor/ and has been pretty darn popular over the last few years. Check it out, and if Diplomacy seems like your kind of game check out http://diplom.org and http://ry4an.org/mn-dip if you're local.
I Buy Liquor For Minors
It's not much of a creation, but I recently made a T-shirt that says, "I BUY LIQUOR FOR MINORS" in nice white on black lettering. I've worn it out a few times including to the Minnesota State Fair, mostly just to gauge responses to the sentiment. It seems the average parent furrows their brow, the average teenager looks intrigued, and the average bartender will still sell me two beers. I didn't actually have a single youth ask me to buy liquor for them, and all the people who actually told me they liked the shirt were in their 20s or 30s. Completely not the responses I expected.
Comments
People in their 20s and 30s aren't as likely to have rebelious, teenage kids. Any plans for an "I Slip Babies the Whiskey Teet" derivative? That might make people in their 20s and 30s a more interesting control group. -- Gabe Turner
Poker Table
As mentioned previously I'm a tool of the media machine and am thus now playing poker. I don't like online play so I host local events here at the house. We're getting more and more people and I wanted something nicer on which to play than folding card tables. Louis Duhon, a friend, and I drew up some plans, bought a lot of materials, moved the cars out of his garage, and spent four days working on a "one day project".
The result was some very nice tables with high end vinyl, velveteen, and birch. For the $250 we spent on materials we could have bought some low end tables but nothing approaching what we ended up with quality wise. Below is a photo and the plans in AutoCAD's DXF format and as a .png. Louis has a lot more photos at http://www.theshadowzone.org/media/poker-tables/poker-tables.html .

Silly Defensive Prompt Coloring
I don't like color in my command line windows. Colorization in ls's directory listings drives me bonkers; it's the first thing I turn off on a new system. I have, however, relented and added a little bit of conditional color to save me from an all too frequent error.
I have access to a lot of UNIX and UNIX-like systems. Some are machines I run, some are my employer's, and some belong to customers. Most all of them I've never physically seen but instead access through remote ssh, secure shell, connections. My normal command line prompt on these machines looks like:
[user@host ~]$
That says I'm on machine 'host' and logged in as 'user'. You'd think that would be enough to alert me when 'host' isn't my normal desktop machine or when I'm logged in as someone other than 'ry4an', but you'd be wrong. After issuing disastrous rm * commands when I didn't notice I was root and after one too many 'shutdown -h' when I didn't realize I was issuing commands to a server in a remote data-center instead of the computer in my closet, I finally wised up and did something about it.
Now when I'm logged into a remote machine the at-sign in my prompt is black-on-white instead of its normal white-on-back. The 'host' portion of each of my prompts is color coded to reflect which machine I'm logged in to, and when the 'user' portion says 'root' it's got a bright red background to let me know that commands are at their most dangerous.
None of this was hard to do, it was all just stuff I finally decided to do. I've attached the shell snippet I put in my /etc/bashrc to do the colorization of the three different parts. The local/remote detection probably only work with the gnu tool chain, but one never knows.
Roomba on the Pronto Remote
A few weeks back I got a Roomba Robotic Vacuum (http://www.irobot.com/consumer/product_detail.cfm?prodid=9) as a wonderful gift. Shipped with it was the optional remote control. The Roomba is fully automatic, but it's programmed to pick up dirt not to chase the cat -- you need the remote for that.
However, long time readers (you poor bastards) will remember that I try to maintain a strictly one remote coffee table (https://ry4an.org/unblog/msg00022.html). That meant the Roomba had to go onto the Phillips Pronto TSU-2000 Universal Remote. I thought for sure I'd find a CCF file for it, but it looks like only the people with newer remotes are getting the Roomba. Fortunately someone in the RemoteCentral forms helped out with instructions on how to back-convert the remote configuration and after a few wasted hours I can now steer the vacuum from the couch. Apparently I became a yuppie when I wasn't looking.
Anyway, attached are the CCF file and a screen-shot.
Dumbing Down scp
The tool scp, UNIX for secure copy, is a wrapper around ssh, secure shell. It lets you move files from one machine to another through an encrypted connection with a command line syntax similar to that of the standard cp, local copy, command. I use it 100 times a day.
The command line syntax for scp is at its most basic:
scp <source> <destination>
Either the source, destination, or both can be on a remote computer. To denote that one just prefixes the file name with "username@machinename:". So this command:
scp myfile ry4an@elsewhere:/home/ry4an/myfile
would copy the contents of the local file named 'myfile' to a remote system named 'elsewhere' and place it in the directory /home/ry4an with the name myfile.
As a shortcut one can omit the destination directory and filename, in which case they default to the home directory of the specified user and the same filename as the original. Nice, simple, handy, straightforward.
However, when you're an idiot in a rush like me in addition to skipping the destination directory and filename you also skip the colon, yielding a command like:
scp myfile ry4an@elsewhere
When you make that mistake scp decides that what you wanted to do was take the local file named 'myfile' and copy it to another local file named 'ry4an@elsewhere'. That's certainly consistent with their syntax -- no colon, no remote system, but it is never what I want.
Instead I go to the 'elsewhere' machine and start looking for 'myfile' and it's not there, and I'm very puzzled because scp didn't give me any error messages. I don't know of anyone who has ever wanted scp to do a local copy, but for some reason the scp developers took extra time to add that feature. I want to remove it.
The best way would be to edit the scp source and neuter the part that does local copies. The problem with that is I'd have to modify the scp program on lots of machines, many of which I have no control over.
So, as a cheesy work around I spent a few seconds writing a bash shell function that refuses to invoke scp if there is no colon in the command line. It's a crappy band-aid on what's definitely a user-error problem, but it's already saved me from making the same frustrating mistake 10 times since I wrote it last week. Here it is in case anyone else has the same un-problem I do:
function scp () { if echo $* | grep -v -q -s : ; then
echo scp: missing colon /usr/bin/scp
else
/usr/bin/scp $@
fi
Just put that in your .bashrc and forever be saved from having a drive full of user@elsewhere files. Or don't; I don't care about you.
Diplomacy at Sea and a Templated Evolver
I've got a policy here on the unblog where I only do entries about things I've created. When I wanted to hype the Diplomacy at Sea V/Dip Con event coming up March 2005 I had to find something to do with it first, so I volunteered to set up their website.
Whenever I need to set up a quick site I head over to the Open Source Web Design site (http://oswd.org/) and pick from their vast array of great designs. This time I went with one called Evolver. It has a clean look and clean code. Rialto did a great job of synthesis and design on this one.
In order to avoid having to edit every page in a site when I want to update a footer or navigation bar I often use Apache's Server Side Includes (SSI) to pull in elements that are on the same on every page. This time I decided to go a step further and see if I could use a single .shtml page for every page on the site. It ended up working out in a fashion sufficiently general to be worth re-distributing.
The outcome can be seen on the https://ry4an.org/dipatsea/ site, though it looks just like Rialto's original design. Attached is a zip-file containing the templatized page and a few paragraphs detailing the necessary symlinks. You'll have to enable .shtml SSIs in your Apache install, of course.
RSS Feed for Security Camera List
I added a RSS feed to the Minneapolis Security Camera Project site. Subscribers to it will see any new cameras as soon as they're posted. If you're not yet using an RSS aggregator let me know and I'll chisel the list on a stone tablet and mail it to you whenever it's updated.
The feed is at http://mpls-watched.org/map/rss.xml
History of the World - Attack Probabilities
History of the World is a fine game from Avalon Hill. It's distributed by Hasbro now, and it's one of the rare Avalon Hill games that Hasbro managed to improve when they "cleaned it up".
History of the World uses dice to simulate combat, and they do so in a way so as to intentionally skew the likelihood of success toward the attacker. There are, however, various terrains (mountainous, ocean straight, forest), types of attack (amphibious), bonuses (strong leader, elite troops, forts, weaponry, etc.) which can affect the success rate of an attacker.
While playing last night we tried to estimate the relative merits of the different troop-efficacy modifiers and found that as if often the case with probability it was difficult to agree even on estimates.
As a result I sat down and wrote some quick Perl simulations to find the numbers for all the various scenarios. This wasn't done in the most efficient way possible, but it's accurate. The terms 'win', 'tie', and 'loss' are from the attacker's point of view.
| Attk Dice | Attk Bonus | Def. Dice | Def. Bonus | Win | Tie | Loss |
|---|---|---|---|---|---|---|
| 2 | 0 | 1 | 0 | 57.87% | 16.67% | 25.46% |
| 2 | 0 | 1 | 1 | 41.67% | 16.20% | 42.13% |
| 2 | 0 | 2 | 0 | 38.97% | 22.07% | 38.97% |
| 2 | 0 | 2 | 1 | 22.38% | 16.59% | 61.03% |
| 2 | 0 | 3 | 0 | 28.07% | 24.77% | 47.16% |
| 2 | 0 | 3 | 1 | 12.96% | 15.11% | 71.93% |
| 2 | 1 | 1 | 0 | 74.54% | 11.57% | 13.89% |
| 2 | 1 | 1 | 1 | 57.87% | 16.67% | 25.46% |
| 2 | 1 | 2 | 0 | 61.03% | 16.59% | 22.38% |
| 2 | 1 | 2 | 1 | 38.97% | 22.07% | 38.97% |
| 2 | 1 | 3 | 0 | 52.84% | 19.23% | 27.93% |
| 2 | 1 | 3 | 1 | 28.07% | 24.77% | 47.16% |
| 3 | 0 | 1 | 0 | 65.97% | 16.67% | 17.36% |
| 3 | 0 | 1 | 1 | 49.38% | 16.59% | 34.03% |
| 3 | 0 | 2 | 0 | 47.16% | 24.77% | 28.07% |
| 3 | 0 | 2 | 1 | 27.93% | 19.23% | 52.84% |
| 3 | 0 | 3 | 0 | 35.23% | 29.54% | 35.23% |
| 3 | 0 | 3 | 1 | 16.69% | 18.54% | 64.77% |
| 3 | 1 | 1 | 0 | 82.64% | 9.65% | 7.72% |
| 3 | 1 | 1 | 1 | 65.97% | 16.67% | 17.36% |
| 3 | 1 | 2 | 0 | 71.93% | 15.11% | 12.96% |
| 3 | 1 | 2 | 1 | 47.16% | 24.77% | 28.07% |
| 3 | 1 | 3 | 0 | 64.77% | 18.54% | 16.69% |
| 3 | 1 | 3 | 1 | 35.23% | 29.54% | 35.23% |
Attached is the script and the same output in various formats.
Bookmarksync Patch for Tab-Group Bookmarks
I use the Mozilla web browser on a few different machines, and its lack of roaming profiles/bookmarks is a source of annoyance. When I bookmark a site on my laptop, I want that bookmark to be available on my desktop machine. In order to achieve that I use a kludgy network of scripts, CVS, crontab entries, and the bookmarksync application.
Bookmarksync (http://sourceforge.net/projects/booksync/) is a tiny little program that takes as input two different bookmark files and outputs the combination of the two. It works just fine in all respects, except that it converts tab-group bookmarks into bookmark folders.
Mozilla has tabbed browsing which means one can have multiple pages open in the same window at once with little index tabs for each. Mozilla also has a feature wherein one can open more than one window and then bookmark the entire set of tabs. Selecting that bookmark in the future will open all the pages that were open when the tab set was bookmarked. I mostly use the feature to keep a bookmark group of all the news sites I read daily. When I select that bookmark twenty tabs spring open, and I just close each one as I read finish reading it.
Bookmarksync (v0.3.3) doesn't know about tab-group bookmarks and instead converts them to just folders full of individual bookmarks. I fired up my C skills for the first time in a very long while and hacked support for bookmark tabs in. I've no idea if I did it well or not, but it works now and that's all that matters to me.
Attached is the patch file and README which was submitted to the project.
foldergroup-patch--bookmarksync-0.3.3.tar.gz
University of MN Magic Number Guessing
Back when I started at the University of Minnesota in 1995 the course registration system was terminal/telnet based. Students would register using a clumsy mainframe-style form interface. When a class a student wanted was full or required unsatisfied prerequisites, the student come supplicant would go to the department to beg for a "magic number" which, when input into the on-line registration system, would allow him or her admission into the course.
Magic numbers were five digits long and came pre-printed in batches of about sixty when provided to departmental secretaries. For each course there existed a separate printed list of magic numbers. As each number was handed out to a student it was crossed off the list, indicating that they were single-use in nature.
As getting one's schedule "just so" was nearly impossible given the limited positions in some courses, and if I recall correctly being particularly frustrated that the only laboratory session remaining open for one of my courses was late on Friday afternoons, I set out to beat the magic number system.
The elegant solution would have been to find the formula used to test a five digit number against the course information to see if it was a match. This, however, presupposes that there existed an actual test and not just a list of sixty numbers for each course. Given than the U of MN had 1000s of courses it's certainly hoped that they didn't design a system requiring the generation and storage of 60,000 numbers, but one never knows. A day spent playing Bletchley Park with previously received magic numbers and their corresponding course numbers found no easily discernible pattern, and given the lack of certainty that there even was one I decided to move on.
A five digit magic number leaves only 100,000 possible options. With at least sixty available per course that's a one in 1,666 chance per guess. Given average luck that's only 833 expected guesses before a solution hits. Tedious when done manually, but no problem for a script.
At the time, Fall 1997, my script-fu was weak, but apparently sufficient. I used Perl (poorly) to create a pair of scripts that allowed me to login, attempt to register for a course, and then kick off a number guesser. In case the registration system had been programmed to watch for sequential guesses, I pre-randomized all 100,000 possible magic numbers and tried them in that order. Given that they didn't even bother to watch for thousands of failed guesses in a row this was probably overkill, but better safe than sorry.
The script worked. My friends and I got our pick of courses for the next few quarters, and despite my boastful nature news never made it back to the U that such a thing was occurring. We only stopped using the system when the telnet based registration was retired in favor of a web based system. Knowing what I now do about automating HTTP form submissions, the web based system would likely have been even easier to game.
The biggest glitch in the system was the fact that magic numbers were single use. Whenever I "guessed" a magic number that was later given by the department to a student, that student's number wouldn't work. However, being given non-working magic numbers was a fairly regular occurrence and certainly not a cause for further investigation on the part of the department. Indeed, the frequency with which my friends and I were given non-working magic numbers leads one to wonder if others weren't doing exactly as we were either using scripts, manual guessing, or by riffling the secretaries' desks.
I've attached a screen-shot of the script in progress from an actual course registration in 1998. Also attached are all the files necessary for use of the original script though since the target registration system is long gone they're only of historical interest. Looking at the code now, I'm really embarrassed at both the general style and the overall design. The open2 call, the Expect module, or at least named pipes would have made everything much cleaner. Still it worked well enough, and I never got caught which is what really matters.
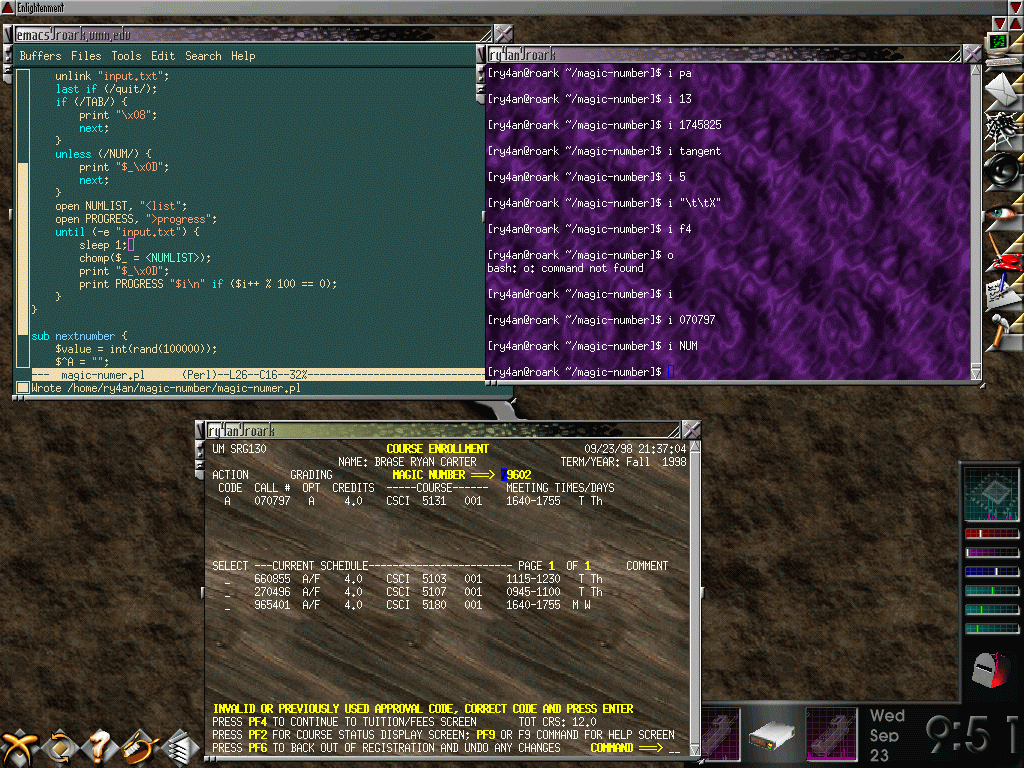
Comments
Doh, had no idea those attachment were as big as they were. Sorry 'bout that. -- Ry4an
Hang on a sec...you're using Emacs in that screenshot! -- Luke Francl
I know, I didn't see the light and switch to vi until 1998. Goes to show you're never too late to repent. -- Ry4an
Turn Sequence Diagram for Kill Doctor Lucky
Cheap Ass Games (http://cheapass.com) make a lot of great games which are available for very little money. A perennial favorite is Kill Doctor Lucky which is sort of like Clue, in reverse, and with a better sense of humor. It's an easy game to learn from the rules, but no one wants to read the rules. I've found that putting this turn sequence diagram I whipped up in front of a first time player augmented with a quick explanation of killing and failure is enough to get someone from zero to playing in 30 seconds. Maybe the computer geeks with whom I hang out are more into state diagrams than the general populace, but it works for us.
The attached image shows the diagram. The attached archive contains the source diagram, a .pdf version, and a the same image.
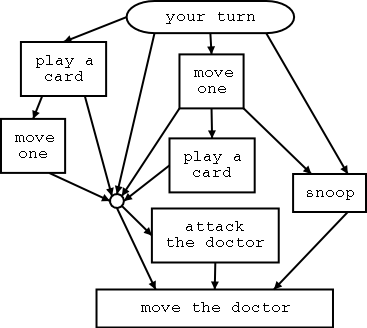
Comments
Sometimes the best things to use are the simplest ones, this works perfectly and takes any guesswork out of the equation for a new player. Now if I only one of the for my life, that would be truly useful! -- Louis Duhon
Dude, we made one for your life... it's blank -- Gabe Turner
Heh. (hate you!) -- Ry4an
Making Driftnet work in Webcollage in Xscreensaver
EtherPEG (http://www.etherpeg.org/) is software for the Mac the listens in on local network traffic, identifies any images being downloaded, and displays them. Driftnet (http://www.ex-parrot.com/~chris/driftnet/) is Linux software that does the same thing, but offers better command line integration. Xscreensaver (http://www.jwz.org/xscreensaver/) is the screen saver/console locking program I use to keep people from using my laptop when I'm getting a refill at my local coffee shop.
Xscreensaver has a display mode called 'webcollage' (http://www.jwz.org/webcollage/) that can use driftnet to show modified images from the network as the screen saver display. So when I'm away from the laptop it pops up pictures from all the websites that everyone else on the wireless network is looking at. At least in theory it does. Actually, I couldn't get it to do that at all.
I'm sure there's a single, simple thing I was missing to make xscreensaver use webcollage use driftnet, but I couldn't find it if there was one. Xscreensaver kept starting multiple copies of driftnet and never finding the images they captured. I had a blank screen saver and a lot of run-away processes. I'm sure jwz, Xscreensaver's author, could've told me what I was doing wrong, but people who ask him questions tend to get found hanging from meat hooks in his club.
I ended up hacking the xscreensaver config and webcollage script to get things working. I've attached a tarball containing instructions and a patch in case anyone else is having the same problems I did.
driftnet-webcollage-xscreensaver.tar.gz
Comments
That is actually very cool, every come back to some questionable content for a public place? -- Louis Duhon
Mostly just friendster stuff, cnn, and sports. You should try out etherpeg, the mac version, it's definitely fun. -- Ry4an
Drink Recipe Fortune File
I like mixing drinks, despite having no real skill for it. The commercial bar-tending courses seem to rely extensively on flashcards for the learning of drink recipes, so I though a UNIX fortune file of drink recipes would be a natural fit for learning.
Unfortunately, I couldn't find any good, public drink listings in a format I could parse. Eventually I found one in CVS from this project: http://drinkmixer.sourceforge.net/ It's not huge, but at least its a start and easily added to.
Output looks like:
[ry4an@home ~]$ fortune drinks Blue Blazer (serve in Old Fashioned Glass)
- 1 1/2 oz. Scotch Whiskey
- 1 1/2 oz. Boiling Water
- 1 tsp. Sugar
Instructions: WARNING USE EXTREME CAUTION! Get two silver plated mugs with handles. pour Scotch and boiling water in one mug. Ignite the liquid, and while blazing pour rapidly back and forth from one mug to another. Pour into old-fashioned glass with sugar.
The nature of the fortune command also makes the recipes search-able using the -m option like this:
[ry4an@home ~]$ fortune -i -m 'Rob Roy' drinks (drinks) % Rob Roy (serve in Cocktail Glass)
- 1 1/2 oz. Scotch
- 3/4 oz. Sweet Vermouth
- 1 dash Orange Bitters
Instructions: Shake well with cracked ice. Strain into cocktail glass. %
The fortune file is probably of no use to anyone actually taking bar-tending classes as everyone's recipes are always a little different, but for the rest of us it's a nice little learning tool.
The fortune file, corresponding .dat index file, source .csv file, and munging script are found in the attached archive.
Poker Timer Configuring Launcher
I got sick of having to edit the launch file whenever I ran my Poker Timer (https://ry4an.org/unblog/msg00038.html), so I wrote a quick CGI that generates a JNLP file which launches the app with the specified settings. You'll need to have a 1.2 or higher Java Virtual Machine installed (http://java.com).
So we've got a Perl interpreter dynamically producing a JNLP file that tells a Java Virtual Machine what to do. Talk about an unholy alliance.
The timer can be run at:
https://ry4an.org/pokertimer/
PokerBot in IRC
I said I wasn't going to do it, but I ended up doing so anyway. I've written a Poker dealing IRC bot. It's not terribly modular and it only supports TexasHold'em, but it works. It requires Perlbot 1.9.5 which is available on source forge. Here's an excerpt from play:
<Dealer> Board now shows: AH 2C 9D 2D <Dealer> joe, action is to you. Current bet is 0. * joe bets 20 <Dealer> joe bets 20. <Dealer> Ry4an, action is to you. Current bet is 20. * joe peeks * Ry4an calls <Dealer> Ry4an calls. <Dealer> Board now shows: AH 2C 9D 2D 2H <Dealer> joe, action is to you. Current bet is 0. * joe checks <Dealer> joe checks. <Dealer> Ry4an, action is to you. Current bet is 0. * Ry4an checks <Dealer> Ry4an checks. <Dealer> joe has been called and shows: 7D 8D <Dealer> Ry4an shows 10C 6C and wins 70 with Trips (2 A T)
Anyway, I've attached the code in case someone wants to take it and make it better or update it to the newer versions of perlbot.
Non-Linear Time Display
A few years back I was working in an office where my workspace was so noisy I kept slipping away to find quieter places in the building to work whenever I has a task which could be completed away from my desk. To avoid looking perpetually absent I wrote a quick script that would display (if available) the contents of a file named I-AM-AT and the how long it had been since I'd last pressed a key.
I fed this simple text output through the xscreensaver (http://www.jwz.org/xscreensaver/) application's phosphor ( ) screen saver which displays text as if were showing up on an ancient monochrome monitor.
) screen saver which displays text as if were showing up on an ancient monochrome monitor.
The end result being anyone could walk by my desk, see where I was, and how long it had been since I'd left. It worked really well, as as an extra benefit those who came in at 6am could see I'd often left just 3 hours previous which quieted grumbles when I'd arrive at 9:30 or 10:00.
The problem started when I began running over lunch again. I'd walk home (15 minutes), run (30 minutes), shower and change (10 minutes), and walk back to the office (15 minutes) -- totalling 70 minutes, a bit more than the 60 minutes everyone generally took for lunch. My taking an extra 10 minutes every day over lunch wouldn't have been a problem really. Times weren't carefully watched, and everyone (by now) knew I often stayed really late, but still having my own computer advertising that I'd been at lunch for 1:10 just didn't look good.
I decided the fix was to have the time reporting on the display not quite, exactly, correspond with real linear time. The fudge factor, though, couldn't just be "subtract 10 minutes". Doing so would mean that initially it would say I'd been gone for negative 10 minutes, definitely a tip off that something wasn't quite accurate. Also to be avoided were any sudden changes in the time. If "gone for 7 minutes" was still visible scrolling off the screen and "gone for 9 minutes" or worse yet "gone for 5 minutes" was replacing it, the game would be up.
I ended up going with a system of strictly linear time for the first 45 minutes of any absence, at which point the rate of time passage would slow and then return to normal gradually (sinusoidally, actually) until at the 1 hour 15 minute mark it was displaying just 1 hour elapsed and time was running at the right rate again. Then an hour later the process would be reversed with a speed up followed by a slow down that would have time back on track after 2 hours 15 minutes total elapsed real time. This kept my overnight elapsed time reporting accurate while keeping my daily runs to about 57 displayed minutes.
Poker in IRC
As seen in the previous posting my friends and I are on a bit of a poker kick lately. As mentioned a good while back we sit in an IRC channel all day while working. I thought it would be fun to find and run a tiny little IRC bot that would deal poker for us. You know a few hands over lunch. No real money of course, just a little diversion. There exist IRC bots that do everything from serve virtual drinks to search google for you. Making a bot that deals poker should be well within the realm of the medium. I expected to find ten poker dealing bots in the usual places and if I was lucky one of them would be decent enough to be usable.
A little googling found that someone wrote a very capable IRC dealer. http://www-2.cs.cmu.edu/afs/cs/user/mummert/public/www/ircbot.html Todd W. Mummert a researcher at CMU wrote a great one. It's stable, full featured, and with a good interface -- and no longer available. What's more there are a plethora of excellent graphical clients written by third party developers that are now completely useless. These developers took hundreds of hours to write nice graphical front ends for a poker system that is now completely unavailable because the author never released the source.
Other searches found a new system in the making from some AI researchers in Canada. They've got a reasonably well designed protocol, for academics anyway, specified ( http://games.cs.ualberta.ca/webgames/poker/bots.html ), and they've even written two libraries one can use to write clients -- for their unreleased server which could, of course, vanish at any time leaving a supporting developer out in the cold.
No one's making money off this stuff, and everyone's insistence on server-side secrecy is just baffling. It doesn't prevent cheating; it doesn't facilitate client testing, and I suspect it keeps the best of developers away from their systems.
For now, we'll be poker-less in IRC, and probably get a little more work done because of it, but if I break down and write an IRC poker bot you can be damn sure the source won't be locked away on my drives so that when I finally grow up and move on whomever next wants to write one can start with my crappy code.
Poker Timer
Some friends and I have been playing poker a couple of times a month for the last year or so. Our play is terrible, no one cares, and we usually spend more on beer than we win. It's a good time.
In November a few of us decided to head to the local card club and try our hands at play in the wild. We decided to enter a tournament. Tournaments are a great way to start out playing at a card club because you know going in exactly how much money you're going to loose from the start. Ninety or so people each pay a fixed entrance free, and only the top nine of them get any prize money at all. Tournaments all offer good initial chip parity -- everyone starts with exactly the same amount of money so you can't be pushed around by bigger stack from the start. Another added bonus is that for your initial buy-in of twenty or so dollars you get a few thousand "dollars" in tournament chips. They're not real money but they're the closest I'll ever come to saying, "I raise 2000," without having to append, "pennies."
The tournament was great fun and though none of us made it into the top 50% of finishers we really liked the betting structure. The tournament was divided into twenty minute rounds each of which had their own amounts for the blinds (like antes) and minimum bets. The constantly escalating financial pressure encouraged aggressive play and ensured a timely conclusion.
Last night the friends were coming by for poker again and wanted to play tournament-style, but we couldn't find any tournament round display software for download. I ended up writing a quick and dirty one poker timer that allows for the display of progressive round values. I would have liked to have displayed it through the TV but lacked the right cables so we just set a laptop where everyone could see it. I've attached the Java source, binaries, and a screenshot.

Shrimp Recycling Only
Last November while sitting in the Atlanta airport with not much to do I saw a bank of six different trash cans. They were in a neat row, each was in a different color, and they were all good for only one thing. People would walk up with a piece of trash and then carefully place it into whichever bin it best fit. Is this bottle glass or plastic? The lid is aluminum does it need to come off? Is this a number two plastic or a number four plastic?
People, actual grown adults, were sorting garbage. If thirty years ago you had tried to tell me that in the next millennium everyone sorts garbage, you'd have failed because I wouldn't have been born yet. But had I been born I suspect I wouldn't have believed you.
Then in my boredom I had a vision, Shrimp Recycling. I wanted nothing more that to watch the people scanning the array of recycle bins to come across one with a logo indicating that shrimp tails and only shrimp tails were to be tossed into it. Would these automatons even notice or would they just pass it over as not-the-aluminum bin? Would they store away the knowledge and start saving their shrimp tails for future recycling? How the hell would you recycle a shrimp tail?
I knew then I needed to make up some shrimp recycling logos I could affix to existing recycling bins in public places. Today I finally got around to it and, well, it's pretty clear I'm not graphic designer. Still, I hope to make them into vinyl labels and see what happens.
Attached is a small copy of the graphic and an archive containing the layered gimp file and an image sized for printing at 8" x 8" at 300 DPI. If I ever get around to actually making the labels and trying 'em out I'll try and post photos.

Comments
Of course shrimp tails would be an excellent addition to any compost heap. There may be other compostable matter in the airport, but who cares.
Your uncle,
-- Jeff
I got email from a few different folks saying that compost rather than recycling would be a better end for shrimp shells. I would have assumed so myself too, but then some googling turned up some pages saying that seafood shells aren't good for compost as they decompose too slowly. Some sites recommended grinding them into a fine powder and using them in mulch to reduce acidity.
Still, I'm mostly interested in how people would respond to shrimp recycling bins. I suspect the majority would pass them by without surprise. Maybe I'll place one in the row of trash cans next to the Lodge at the lakes this year and stake it out.
-- Ry4an
Improving the RCA RP3711 Alarm Clock
I live in a sleep deprived state. Not just because I have a lot to do and resent sleep as the short-term death it is, but also because I enjoy the swirling colors. Maintaining a sleep deprived state requires a good alarm clock. When your brain knows it needs 8 hours and you're giving it 4 it's gonna fight you, and given that it's in charge of your perceived reality, it doesn't have to fight fairly.
Buying a good alarm clock is an exercise in frustration. The features advertised on the box are seldom relevant, and the most important ones are never mentioned. In the absence of a plugged in display model one is left to read the labels on the buttons or if available a manual to try to see how the thing actually works. Two features which cannot be omitted without ruining the clock are:
- Turning the alarm off must leave it ready to go off again the next day without having to switch it back on.
- The snooze button must be much larger than the off button.
The first of those two is the most important and has only really been available since microprocessors driven solid state buttons became cheaper than sliding switches. Unfortunately I've never seen a clock box explain whether or not turning off the alarm leaves it ready for the next days horrible awakening. Sure, this means that sometimes the alarm goes off on Saturday because I forgot to turn it off for the weekend and that my neighbors hate me when I go out of town, but until I see a clock that knows weekends from weekdays default-on is better than manual-select.
The snooze button to power button ratio is nearly as important. After my eighth snooze my brain is loudly explaining to my arm that everything would be much better if it would just "accidentally" hit the power button instead. The arm must not be allowed plausible deniablity.
Three years back I finally found a great alarm clock. The RCA RP3711 http://www.epinions.com/content_54115470980 meets the two must-have requirements. It also offers:
- digital radio tuning (no more having the tuner drift to silence)
- adjustable snooze time (why are most 7 or 9 minutes?)
- forward and backward motion in alarm and time setting
- battery backup
- a nice "nap timer" that chimes after 20 minutes to 2 hours without having to reset the primary alarm time
It's a great clock and I intend to pick up a few as back-ups in the future. Unfortunately, the power-off button is just a little too easy to hit. It's not at all easy to confuse for the snooze button (it's a teal circle up top as compared to a large silver dome on the front), but it can be hit from above with a ham-fisted swat which is just a bit too easy. For years I've corrected this by taping a small circle of plastic over-top the power button. When I was finally willing to actually get up and turn off the clock I'd flip up the cover and then press the button -- sort of like firing missiles in a fighter jet.
However, with things as busy as they've been at work lately I'm running on even less sleep than normal and Brain has been tricking Arm more reliably. A few times as of late I've woken up hours after I should have and Brain is all, "Arm must have done it," and Arm is all, "Nope, Torso was laying on me."
To fix this I decided to take apart the clock and see what could be done about making the power button harder to press. I was envisioning adding another push button in series with the existing one necessitating the pressing both at the same time to shut it off. If these two buttons were on opposites sides of the clock and more than a hand span apart actually waking up when turning the clock off would be almost assured. If a length of cable with two wires in it was used the power button could even be removed from the clock altogether and placed over by the door -- now that's safety.
Unfortunately the little micro-switch was a surface mount component and getting it loose was going to take better soldering skills than I have. I had to settle for snipping off the plastic caps for the volume control and power switch. Now to turn the clock off one must carefully place a finger deep into the gaping hole on the top of the clock and depress the tiny micro-switch. Indelicate button pressing results in a miss and likely an electric shock -- that'll teach Arm to listen to Brain.
Comments
When I was 10 years old, I picked up a Sony "Dream Machine" (ICF-C370). Not only does the alarm stay set, it requires pressing two buttons to turn it off. Not in succession, either, you have to press them both in the proper order - first the 'Alarm' button, and while holding that down, the 'Alarm on/off' button. I've been using this alarm for 15 years and it's performed flawlessly. Although I'm extremely happy with it, I find myself requiring more, as of late. See, I'm not some gimp that requires the use of the snooze button. My problem is that the snooze button is so large that I accidentally hit while fumbling to turn the alarm off. Then, while I'm happily showering or something, it starts going off. I need a way of reducing the size of the snooze button, or disabling it entirely. Also, my clock makes annoying clicking noises if I set my phone to close to it... I'm sad that the alarm clock market sucks so bad now... I really want to find a good one -- Gabe Turner
Net::Friends for GPSDrive
GPSDrive (http://www.gpsdrive.de/) is nifty software for Linux that turns a laptop and a cheap GPS receiver into a vehicle navigation system. It displays maps, records tracks, logs speed traps, and all the other little features you'd expect in a system trying to divert your eyes from the road.
It also sports a built-in system for networking with other GPSDrive enabled systems on the road to mutually plot one another's locations. The system, called friendsd, uses a simple UDP server to record and report the position, speed, and heading of other reporting systems on the same server. Of course, this reporting only works if the laptop has access to the Internet but with the various cellular and wi-fi systems available that's not so much a stretch.
I've got a silly little project in the works for using friendsd in a manner other than its original intent, but I needed to be able to interact with it using something other than GPSDrive as the client. To that end I wrote up a little Perl module, Net::Friends (attached), that provides for basic reporting to and querying from friendsd servers. I think it game out pretty well.
The Flaming Moe
For the last three years Cari, Bridget, Joe and I have co-hosted a Halloween party at Cari's and my place. Every year I man the bar because I enjoy doing so and like the chance to talk to everyone periodically over the course of the night. This year I decided to turn the role into my costume and dressed as Moe Szyslak, the bartender from The Simpsons.
In one particularly good third season episode, titled "Flaming Moe" (http://www.snpp.com/episodes/8F08.html), Moe finds great success serving a drink whose recipe was stolen from Homer. The drink, which Moe calls the Flaming Moe, includes as its secret ingredient Krusty Brand non-narkotik cough syrup and erupts into quickly retreating pillar of flame when lit. I figured if I was gonna do Moe I had to make that drink.
I started with the drink base and after many failed attempts to make that was (1) classy, (2) tasty, and (3) grape, I gave up on the first two and just went with grape kool-aid, grape pucker schnapps, and triple sec. It was palatable. After pouring that base in from a pitcher I'd then add just a little "cough syrup" (grape sugar syrup) from a re-labeled nyQuil bottle.
For the column of fire effect I'd place the drink in front of a tea light I had sitting on the bar, and would then use a salt shaker to sprinkle from above a cascade of non-dairy creamer onto the candle. When I got the concentration just right (too much and you extinguish the candle, too little and nothing happens) the non-dairy creamer would flare up in a foot tall fireball which looked for all the world like it was coming out of the glass. Unfortunately it only worked about one in ten times.
Below is a photo of the tail-end of one of the flare ups, and the illusion isn't bad. Thanks to Jan Creaser for the photo. Also attached is a small image of the label and an archive containing a full-size version printable at 300dpi for bottle modification.


Lying to Myself About Calendaring
Three days ago I posted a rather lengthy entry wherein I decried the current state of open, collaborative calendaring. In it I listed six requirements for calendaring software and settled on the option available to me that met the most of them. Now I'm changing my mind.
At the time I needed a new calendaring solution fast and had checked out all the candidates before. The software package Remind had a nice interface, an expressive configuration language, web-visibility, local-storage, and was open source. It met four of the six requirements and would have served admirably for a few years. So why did I find myself laying awake worrying about my choice? (Seriously, I'm that big of a loser.)
The cause of my mis-selection was part haste and part willful self-deception. I wanted to go with Remind because I knew working with it on a day to day basis would be a joy. Toward that end I manipulated the selection criteria to favor Remind. The six requirements I listed are valid, but using a bullet list rather than a sorted list presents them as being all of equal import, which just isn't the case.
In The Cognitive Style of PowerPoint Edward Tufte addresses bullet points saying, "For the naive, bullet lists may create the appearance of hard-headed organized thought. But in the reality of day-to-day practice, the [PowerPoint] cognitive style is faux-analytical." He then goes on to explain how PowerPoint caused the Columbia space shuttle disaster.
Sorting my list of six requirements by importance (most important first) yields:
- standard data format: for easing inevitable migrations; vCal/iCal lately
- stored locally: I prefer to host my own data
- free: as in speech and as in beer for all the obvious reasons
- text-mode access: I prefer text mode to GUI applications
- web access: at least viewable (preferably editable) on the web
- groupware capable: ability view others' calendars and publish mine
Even that doesn't show the relative weight given to each requirement. A representation displaying importance would show that the first one, standard data format, is probably more important than all the rest put together.
As mentioned previously the Remind file format is great to work with, but no other software uses it. What's more as one became more proficient with remind one's event entries would get more complicated, making eventual migration all the harder. I'm not willing to ghettoize my data, so Remind has to go.
When limiting myself to the current calendaring data standards (vCal, iCal, and xCal) the list of options shrunk dramatically. There were no text-only options and the web-based options were all painful. I looked into Ximian's evolution (http://www.ximian.com/products/evolution/) but it was slow and insisted on storing data in ~/evolution. I ended up deciding to run Mozilla Calendar (http://www.mozilla.org/projects/calendar/). It's nice enough, actively developed, has good standards compliance, and runs inside the only non-text application I always have open, my web browser.
Anyway, getting my phpGroupWare data into Mozilla Calendar just meant writing another conversion script. This one, phpGroupWare to iCal, (attached) might at least be useful to someone other than me.
This whole process undoubtedly seems silly, but at its core is a firm rule for data longevity: store your data in open, standard, lowest-common-denominator formats. Ask any company with 10,000 word processor documents that can no longer be read using their new software. Closed data formats are manacles that can be a hassle over the course of decades scale and tragic on a historical time scale.
Calendaring Migration
I'm happy with my email client, text editor, compilers, IRC client, news reader, web browser, and just about every other tool I use in the process of my daily computing. The only consistent source of displeasure has been my calendaring (when the hell did that become a word?) application. I have a hideously over-scheduled life and need some sort of scheduling solution be it computerized or otherwise to keep things straight, but I've never found anything that really suits me needs.
Over the last 10 years I've used and discarded a number of solutions, including a paper notebook, palm pilot, gnomecal, and phpGroupWare. Each of them has had their advantages and their drawbacks, but none of them has been perfect. Wherein 'perfect' meets these requirements:
- standard data format: for easing inevitable migrations; vCal/iCal lately
- free: as in speech and as in beer for all the obvious reasons
- text-mode access: I prefer text mode to GUI applications
- web access: at least viewable (preferably editable) on the web
- stored locally: I prefer to host my own data
- groupware capable: ability view others' calendars and publish mine
To my knowledge nothing out there yet handles all of these requirements. Likely nothing ever will, but so long as they use a standard interface to a data back end I'll be able to mix-and-match sufficiently to reach calendaring nirvana.
There are, however, many applications that do an excellent job with some of the requirements. Apple's iCal (whose horrible name creates confusion by overlapping that of an established data standard) uses the standard iCal data format and WEB-DAV for good groupware-ness, but they've locked down the groupware functionality to their .mac boondoggle and aren't sufficiently free. phpGroupWare doesn't use standard data formats and is pretty krufty in general. Sked (http://sked.sourceforge.net/) has a great interface but uses non-standard data storage and doesn't seem to be actively developed any longer. Reefknot (http://reefknot.sourceforge.net/) was a promising iCal groupware back end until it was apparently abandoned.
On the horizon is Chandler from the OSAF (http://www.osafoundation.org/) which is promising a good, decentralized-groupware, standard-data-format back end that would allow for text, GUI, and web clients. I'm trying not to get my hopes up because if 10 years of looking for a decent calendaring solution has taught me anything it's that they'll shoot themselves in the foot somehow.
For the time being I'm moving to remind (http://www.roaringpenguin.com/remind/). It's free, text mode, offers web viewing, and stores my data locally. It doesn't offer any sort of groupware capabilities, and perhaps worse yet has a completely non-standard data format. Moving my existing data (exported from phpGroupWare) into remind's human-editable format required just a few simple conversion scripts (attached), but moving back out of remind's powerful storage format to something more standard (again likely vCal) will be a real nightmare.
If anything I'd say my decision to switch to the hard-to-migrate-from remind application shows my pessimism that anything sufficiently better to be worth switching to will be available within the next two or three years.
IRC Nickname Tracking Script
Being a telecommuter, the closest thing I have to an office is an IRC channel. IRC (Internet Relay Chat) is like a chat room minus the emoticons and pedophiles. While normally the office IRC channel is the very embodiment of maturity, there are two silly things about it that have always annoyed me. The first being that everyone gets to pick their own name, and the second being they can change their names at will.
When everyone can pick their own name you end up with a lot of all-lowercase, powerful sounding names for people you think of as Jim and Bob. If everyone has their own terminal on which they're viewing the channel's discourse there's no reason why we can't all see each other referenced by whatever name we're most comfortable calling the person.
Worse yet is the ability for everyone to change their names. Occasionally, and I've no idea what triggers it, everyone will start switching names willy-nilly to new and sometimes each other's names. This is like going to a costume party where everyone keeps switching masks every few minutes -- eventually someone's gonna kiss someone else's girlfriend.
Because I'm cantankerous and have too much time on my hands, I wrote I little script for the excellent Irssi IRC client I use ( http://irssi.org/ ) that mitigates the hassle from both of the bits of silliness mentioned above. Using my script I can issue commands of the form "/call theirnick whatIcallThem" and from then all messages from the person who was using the nickname "theirnick" will now show up as from "whatIcallThem", and it will do so regardless of how many times they change their nickname.
Is it perfect? No. The people in the channel still refer to one another by their nicknames so I still have to decode nick -> human mappings in my head, but at least not so frequently. At any rate, the script is attached. It is known to work with Irssi v0.8.6.
Comments
This script has been updated in a recent entry.
Email to SMS Conversion
There's a program on freshmeat called email2sms (http://freshmeat.net/projects/email2sms/) that runs emails through a series of filters until they're short enough to be sent to a cell phone as a SMS message -- which typically have a maximum length of 150 characters. The script is mostly just a wrapper around the nifty Lingua::EN::Squeeze Perl module.
Squeeze takes English text and shortens it aggressively using all manner of abbreviations. It leaves the text remarkably readable for being about half its original length.
I ran the email2sms script for just a few weeks before running into a problem where an address sent to me by a friend was mangled past the point of usefulness. I figured that the best fix for that problem was to enlist the sender to evaluate the suitability of the compressed text.
To achieve that I added a feature to email2sms wherein a copy of the compressed message is sent back to the original sender along with a request that if important details were lost from the message during the compression process that they shorten the message themself and re-send it or send it to an alternate email address I provide on which no compression is done. The reply system has worked out quite well, and in the three years I've had it in place there have been a few circumstances were a human initiated re-send has saved an otherwise mangled message.
Attached is my version of the email2sms script, the configuration files I use with it, and a procmail recipe to invoke it. For fun here's the text of this post compressed by Lingua::EN::Squeeze.
ThersProgramOnFrshmatCllEmal2sm(URL/)RunEmalThrghSreOfFiltUntlT/reShor tEnoghToBeSntToCllP8AsSMSMsg--W/TpclyHvMaxLengthOf150Chr.ScriptIsMostl yJstWrappArondNiftyLng::EN::sqzPrlMod.SqzTakEngTxtAndShortenItAggresvl yUsngAllMannOfAbbrevitonItLeaveTxtRemrkblyRedble4BngAbotHlfItsOrgnalLe ngthIRanEmal2smScript4JstFewWekBfreRunnngIntPrbWherAddresSntToMeByFrnd WasManglPstPntOfUsflnesIFigurBstFix4PrbWasToEnlistSendToEvaluSuitablty OfCompressTxtToAchiveIAdddFetreToEmal2smWhrinCopyOfCompressMsgIsSntBck ToOrgnalSendAlongW/RqestIfImportantDtilWerLstFromMsgDurngComprsonProcT /ShortenMsgThemselfAndRe-sndItOrSndItToAlternEmalAddresIPrvdeOnW/NoCom prsonIsDon.ReplyStmHasWrkOutQuite,AndInThreeYYIveHadItInPlacTherHvBenF ewCircmstnceWerHumanInttedRe-sndHasSavOthrwseManglMsgAttachedIsMyVerOf Emal2smScript,ConfigurtonFilIUseW/It,AndPrcmilRcpeToInvokeIt.4FunHersT xtOfThiPstCompressByLng::EN::sqz
Philips Pronto TSU-2000 Remote
I try to lead a very uncluttered life whether one's talking about hard drive layout, personal responsibilities, or physical clutter in my condo. Three years ago I got my first TV and DVD player. Each came with its own remote control. Not wanting to deal with two remotes on my coffee table (which at the time was a cardboard box) I went out and bought a nice $20 universal remote that was very programmable and easily handled the functions of both the TV and the DVD player.
Since then I'd added a TiVo and a VCR to the mix and the old remote just wasn't cutting it. Looking through Remote Central (http://remotecentral.com) it looked like my options were cheap remotes with fixed buttons whose labels would never match their assigned functions or ungodly expensive remotes with touch screen buttons and programming software run on one's computer.
Finally last week after the release of the brand new TSU-3000 remote, the price of a refurbished TSU-2000 (four generations older) dropped into my price range. The TSU-2000 (http://www.remotecentral.com/tsu2000/) has a few hard buttons around the edges for the functions you want to be able to use without having to look at the remote (volume, pause, etc.) and a large touch screen area in the center for everything else.
Reading reviews for the TSU-2000 shows that owners are divided into 2 categories: those who are geeks and those who find the remote unacceptably difficult to program. Everything about the remote is user-definable from the location and shape of the buttons to the screen transitions to the pitch of the beeps.
The software it comes with, ProntoEdit, is (I'm told) terrible, but it only runs on windows. I found a Java implementation called Tonto (http://giantlaser.com/tonto/) which has worked wonderfully thus far. It probably took a good 20 hours for me to get my remote to the point where my configuration handles most of what I need it to do, and even that was with liberal use of other peoples' graphics. Is the flexibility worth the time investment? Probably not for most people, but still there's something nice about being able to make the commercial skip button on the TiVo as big as a quarter.
Comments
So... how much did you pay? -- Gabe Turner
$120 for the refurbished unit on ebay -- which seems about average for the TSU-2000s. List that's a $350 remote. The color ones (TSU-6000) are $700 list and seem to go for about $350 refurb on ebay. The new TSU-3000s look nice but I don't know if there's a refurb supply yet. -- Ry4an
Canoeing with a GPS Unit
This weekend I had a great time canoeing with six friends. We camped, swam, paddled, drank and just generally goofed around for a weekend. Two of us had brought along Garmin eTrex GPS units which I'd not previously had when canoeing. They really added a lot.
I built an 18 point route approximating our course before hand and loaded them into the GPSs. With that info and the GPS's natural data collection we were able to always know our current speed, average speed (3.2 mph), max speed (mine = 10.5 mph), distance paddled (total = 29.1 miles), and elapsed time (10 hours 31 minutes of paddling).
When we got back I took the GPS units and dumped their track history data to my computer. Using the attached garbleplot.pl script, it made the attached image of our course. The x and y scales are internally consistent in the image, but can't be compared with each other as the distance represented by a degree longitude and that of a degree latitude are different anywhere but the equator. The GPS data has a much higher level of precision than the pixel resolution in the image can show. At a higher zoom level the red and green lines would should Louis's canoe cutting a nice straight line down the river while mine zig zagged its way along the same general course.
Email Response Times
I get and send a lot of email. Many of the emails I send are responses to emails I received. When I respond to email I almost always quote the email to which I'm responding, and when I do my email client (mutt) inserts a line like:
On Thu, Jan 02, 2003 at 11:40:25AM -0600, Justin Chapweske wrote:
Knowing the time of the original message and the time of my reply provides enough information to track my response times to email. I used the inbound message ids to make sure only the first reply to an email was counted.
I whipped up a little Perl script to extract some stats and create a histogram. The script and histogram are attached. Here are some of the stats I found:
- Of the 1888 emails I've sent during calendar 2003 thus far 1128 of them were replies
- My five most common response times in minutes were:
- two minutes: 59 times
- four minutes: 45 times
- one minute: 44 times
- three minutes: 41 times
- seven minutes: 33 times
- My mean response times was 20.3 hours.
- My longest response time was 386 days to some guy from whom I want tobuy a domain.
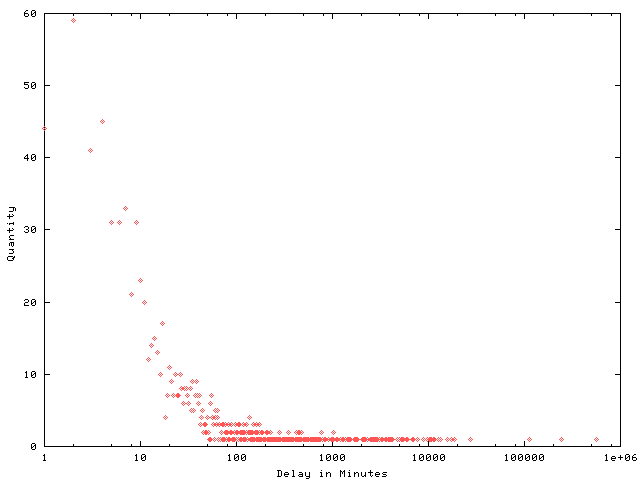
WikiChump
A chump bot (http://www.w3.org/2001/09/chump/) sits in an IRC (Chat) channel and remembers any URL (web addresses) that people say. It displays them on a web page for later reference. I spend time in #infoanarchy on the freenode network (freenode.org) where someone runs a chump bot whose output is visible here: http://peerfear.org/chump/
A wiki is website anyone can edit. Every page has an edit button on the bottom which anyone can press to edit the page. They grow organically and are great for group collaboration. Some friends and I set one up and track plan most of our group activities using it. The most famous wiki is http://c2.com/cgi-bin/wiki?WikiWikiWeb
I wanted to combine these two resources so that anything said in the IRC channel my friends and I chat in was recorded on the wiki we share. I sat down and Perl script to do just that and it took surprisingly little time. Yay for the HTML::Form module. The output can be seen here: http://www.arioch.org/phpwiki/index.php/WikiChump
Attached is a tarball containing that script.
Hand Scanner
Some friends and I just threw a huge party with a Dystopian future theme. I wanted to have a hand scanner at the door because biometrics scare the hell out of me. I started out with grand plans involving laptops and real scanners and all sorts of things like that, but as time drew short I resorted to trickery.
We ended up with a stainless steel cylinder (trash can). Atop it was supposed to be a black glass sheet against which palms could be pressed, but I accidentally shattered that while working on it the night before the party. I ended up using some black foam core board with a white palm on it that looked okay.
When someone pressed their palm against it the 'accept' light glowed and a pleasant ding noise was heard. If, however, we were pressing the hidden, remote button they'd be denied. Denial just meant a different bulb and an unpleasant buzzer.
What's funny is I didn't use use any electronics knowledge past what I learned reading The Gadget Book by Harvey Weiss when I was in the second grade. Since then I took three years of electrical engineering, but none of it had half the impact of that silly little book.
I don't know if anyone took a picture of the finished scanner, but I snagged the schematics as penciled on my mimio white board.
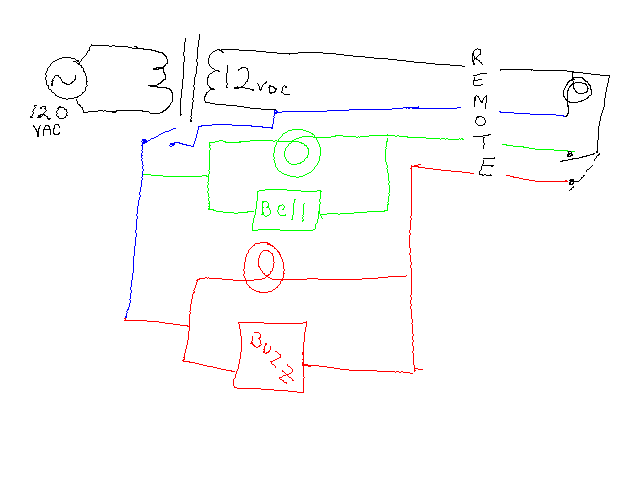
Mailman Non-Subscriber Message Auto-Rejector
I run a lot of mailing lists on mailman, http://www.list.org/, servers. Most all of these lists are configured so that only list subscribers are allowed to post messages. I do this because these lists get a lot of spam messages that I don't want to get through to all subscribers.
Unfortunately, when a non-subscriber posts they're not automatically rebuffed, but instead I, as the mailing list administrator, get an email asking if I want to approve their message anyway. If I don't answer that question I get get a reminder every 24 hours. The reminders can be turned off, but there are some of mailman's questions that I do want to have brought to my attention (ex: subscribed posters who have exceeded maximum message size, etc.).
What I wanted was a way to configure a mailman list so that non-subscribers get a message explaining why their post isn't being accepted without me having to go click 'reject' on a web form. I started to add this feature to mailman, but that wouldn't really wouldn't help. I can't get source forge or my company to upgrade to the newest version of mailman even if my features gets accepted, and those are my lists that get the most spam.
Instead, I wrote a filter that catches email indicating a non-subscriber user has posted to a list and automatically goes and clicks 'reject' on their message. I've got the auto-clicker coded up pretty carefully such that any pending requests that aren't non-subscriber posts won't get auto-rejected. Also, if there's any sort of error in the process the initial notification message is allowed through.
The whole thing fits into a nice tidy Perl script. It's invoked via procmail and requires the excellent LWP suite of modules available from CPAN. The script is attached.
Last Surveillance Camera Post
I got permission from Derek Tonn at tonnhaus design to use his map on the site, and I got the new site fully setup at http://mpls-watched.org. With all that done I figured it was time to send out press released and fired them off to the Strib, City Pages, Rake and Skyway News. Who knows, maybe one of 'em will run something.
When I wasn't sure if I'd be able to use the tonnhaus map, I was trying to figure out ways to make my gathered location data still useful. As mentioned I took some GPS points to test the theory that the map was to scale. I then marked those same four points on the tonnhaus map and calculated the X and Y pixel/degree ratios for each of the six ( (4-1)! ) runs.
If the map was perfectly to scale, and my GPS was perfectly accurate, and my point selection on the map was a perfect correlation to where I stood when taking the GPS points the horizontal and vertical pixel/degree ratios would be the same for all six pairs of points. Unfortunately, they were way off. I'd've written the map off as not to scale if it hadn't been for how very off the ratios were. Not only were they of wildly different magnitudes, but some of them even had different signs. That shouldn't be possible no matter how skewed the scale was.
I spent a good hour puzzling out how my calculations could be so far off when it hit me. Minneapolis isn't built on a real north/south/east/west grid. It's horribly skew. I'd made the rookie mistake of assuming top of the map is always north. I got out a protractor, make a quick measurement, rotated the tonnhaus design map 22 degrees, re-picked my points on the map, re-did my math and found nice reasonably similar rations. After I though out the shortest pairs between points (as short runs maximize error) I got the percent standard deviation for both the horizontal and the vertical down to small enough values that I think converting points of the digital map to latitude/longitude coordinates will be sufficiently precise to make my data portable. Whew.
Surveillance Camera Website
It took most of a weekend to do it, but there's now a nice website for the Minneapolis Surveillance Camera Project at http://sarinity.com . I'll be moving it to its own domain eventually, but that'll be a week or so.
The look is entirely owed to the Open Source Web Design site, http://oswd.org. I love being able to just go snarf a well coded template for a new project. Those people are doing a real service.
The meat of the new site was done in Perl by myself. One can now view camera locations, information, and pictures, report cameras, and upload photos of cameras.
I heard back from the Derek Tonn of tonnhaus design about using the map, and he's understandably interested in seeing how the project comes out and what it's about before he provides the tacit approval implied through the use of his base map. If I need to switch over to another map it shouldn't be a hassle, I just despair finding one as pretty as his.
Update: I've shut down this site.
Surveillance Camera Reporting
I got the surveillance camera location reporting stuff working tonight. It's amazing how easy Perl's CGI.pm can make stupid little web input forms. I'm sure I'll think of some other fields that I want in the data before this thing goes live, but for now this should do nicely: https://ry4an.org/surveillance/report/
The map I'm using is nice, but doesn't include all of downtown, and I still haven't heard back from its creators about getting permission to use it. Since I might have to change maps in the future (or might want to expand project scope) I'm hoping to store the camera locations as GPS coordinates rather than as useless pixel locations.
Toward that end I walked to the four corners of the map tonight while taking GPS readings. I'll import the data later and see if the map is to scale in addition to being aesthetically pleasing. If it is, extracting latitude and longitude data will be a snap given that the spherical nature of the earth can be ignored for areas a small as downtown Minneapolis. If it's not, I'll probably have to find a new map before too many cameras get entered.
Next steps are:
- Coming up with a decent data storage format
- Writing rending code to display the camera data
- Making the website attractive and filled with text
- Begging my friends to help me inventory cameras
None of those should be terribly hard. Who knows within a month or so this might actually be a project worth looking at.
Update: I've shut down this site.
Minneapolis Surveillance Camera Project
Target Corporation is donating a quarter million dollars to the city of Minneapolis, which city council rapidly accepted, to install 30+ police monitored security cameras. I'm not able to articulate why stuff like this scares me as much as it does, but I just get a queasy feeling when I think of government surveillance of the citizenry.
The ACLU has found that police cameras do not yield any significant reduction in crime, and there are many documented instances where police cameras have been used to illegally and inappropriately infringe on the privacy rights of citizens. That said, I think keeping camera counts down is a losing battle. Most people just can't get worked up about privacy rights in general and security cameras specifically.
The New York Surveillance Camera Project (http://www.mediaeater.com/cameras/overview.html) has produced a great map (http://www.mediaeater.com/cameras/maps/nyc.pdf) of all the thousands of Manhattan area cameras they could find. I'm looking to do the same thing for Minneapolis. I guess the hope is that people will be started when they see how frequently they're recorded and will at least think next time the government wants to put up more cameras. Who knows maybe given enough time we can even set up a least-watched route finder like the people at iSee have (http://www.appliedautonomy.com/isee/).
For now all I've done is define an XML format for representing camera information (https://ry4an.org/surveillance/camera.xml and http://ry4an.org/surveillance/camera.dtd). The next step is to get a nice map of downtown Minneapolis (hopefully from tonnhaus design: http://www.tonnhaus.com/portfolio/city_area.htm) and create an image map and corresponding CGI form so friends and I can start entering locations. Lord only know when I'll have time for that.
Update: I've shut down this site.
Symlink Re-Creator
At Onion Networks our CVS repository has a lot of symlinks that need to exist within it for builds to work. Unfortunately, CVS doesn't support symbolic links. Both subversion and metacvs support symbolic links but neither of those are sufficiently ready for our needs, so we're stuck with creating links manually in each new CVS checkout.
Sick of creating links by hand, I decided to write a quick shell script that creates a new shell script that recreates the symlinks in the current directory and below. A year or two ago I would have done this in Perl. I love Perl and I think it gets an undeserved bad wrap, but I find I'm doing little one-off scripts in straight shell (well bash) lately as others are more inclined to try them out that way.
Doing this in shell also gave me a chance to learn the getopt(1) command. Getopt is one of those things is you know is always there if you need it, but never get around to using. It's syntax sucks, but I'm not sure I could come up with better, and what they've got works. While writing my script I kept scaling back the number of options my script was going to offer (absolute, relative, etc. all gone) until really I was down to just one argument and could've put off learning getopt for another few years. O'well.
Once I'd written all the option parsing stuff and started with the find/for loop/readlink command that was going to print out the ln commands, I noticed that by using the find command's powerful -printf action I could turn my whole damn script into a single line. At least my extra wordy version has an integrated usage chart.
Here's the one line version:
find . -type l -printf 'ln -s %l %pn'
Attached is my script that does pretty much the same thing.
False Point Filtering on the Mimio
I'm trying not to have all the projects and ideas posted to this list be computer related, but I guess that's where I expend most of my creative energy. I bought a Mimio electronic white board (http://mimio.com) cheap on eBay ($40), and while the Windows software for it is reported to be quite good, the Linux software options ranged from vapor to unusable. I did, however, find some Perl code that handled protocol parsing (the tedious part), so I started with that.
The white board part of it was largely uninteresting, but one fun problem cropped up. The Mimio infrequently reported false pen position data that caused the resulting image to have some terrible lines across it. An example of the out with the bad data can be found in the attached unfiltered.png image.
To filter out the bad points I started by tossing out any line segments that were longer/straighter/faster than a human should reasonably be drawing. Essentially I was taking the first derivative of the position data and discarding anything with too high a speed.
Always one to go too far I modified my filter so it could take Nth order derivatives. I ended up configuring it to take the first four derivatives of position (velocity, acceleration, jerk, jounce[1]). I could've set it to 100 or so, but I figured with the time resolution I had I was already pushing it.
I experimentally arrived at threshold levels for the scalar magnitudes of each derivative using the ophthalmologist technique ("this or this", "this or this"). The end result for the same image can be viewed in filtered.png. The missing lines that should be there correspond to when I didn't press the pen down hard enough and are actually missing in the unfiltered image as well. It's still not perfect, but it's good enough for me, unless someone else has a cool filtering idea I can try.
I've attached the tarball for the software for posterity. If you're using it email me first -- I might have a more current unreleased version.
[1] http://math.ucr.edu/home/baez/physics/General/jerk.html
Jump to New Feeds in Amphetadesk
Amphetadesk (http://www.disobey.com/amphetadesk/) is a great RSS feed reader. I use it to track 20 or so different news sources a day. However, I mostly subscribe to feeds that include copious content, and once I determine there are no new entries on a feed I still have to scroll down fifteen screens worth of old content to see the top of the next feed.
To speed the process I make a quick 5 minute template hack that provides a "jump to next" link in the title banner of each entry and a corresponding anchor in each title. Since the jump link is always in the same place relative to the start of each new feed listing, I'm able leave the mouse in one place and check the top of each feed w/ just a series of clicks. Like I said handy, but trivial.
Attached is the diff for index.html to add this little hack. I created an ugly 13x13 next.gif in the icons directory which is also attached.

Comments
Why not just have AmpDesk display most recent first? This is how News Monster (http://www.newsmonster.org) sorts your news by default. I lick it. -- Gabe Turner
Yeah, I never understood any Amphetadesk doesn't do that. So nearly as I can tell it sorts by "most recently polled first" without paying attention to whether or not a change happened on that poll. I'm running an older version, and it might be better in newer version. -- Ry4an
Now if only Morbus would keep working on Amphetadesk and fix this problem. I really want to be able to delete weblog posts. -- Luke Francl
Perseverance as Measured with Google Hits
I was eating outside a few weeks ago and saw a sign for the 2nd Annual Cabanna Boy Contest at a local bar. I wisely decided not to enter the contest, but then started to wonder if they had called their first one the 1st Annual Cabanna Boy Contest. That's pretty optimistic. I then started wondering how likely it is that a 1st Annual leads to a 2nd Annual to a 3rd Annual. Being a modern geek I figured google would know the answer if I asked right.
I searched for each each of "1st annual", "2nd annual", "3rd annual" though "15th annual", the cardinal numbers, and "first annual", "second annual", "third annual" through "fifteenth annual", the ordinal numbers, and recorded the hit count for each. The raw data when plotted looks can be found here: https://ry4an.org/perseverance/
While years (x) is >= 2 it looks like an asymptote headed toward zero. Something in the y = N/x form give or take a translation. It wouldn't be too hard to find a fit curve, but that'd be too geeky even for me.
Blogging 1990s Style
My good friends Luke (http://justlooking.recursion.org/) and Gabe (http://twol.dopp.net/) are working on a project that archives mailings lists to blogging software. Essentially something that subscribes to lists and gateways to posts in a blog. I politely told them the idea didn't make sense to me and instead advocated just putting a blog-look onto existing mailing list software. This is my attempt to put my money where my mouth is.
Vanity mailing lists are nothing new, and I subscribe to quite a few of them. Usually they're just one person talking about whatever pops into his or her head. One of the best belongs to Kragen Sitaker and can be found here: http://www.canonical.org/~kragen/mailing-lists.html .
Some of the advantages of a vanity mailing list with a blog veneer are:
- Push-model available for those who want to subscribe
- Threaded discussion is integral to the system
- Can create blog entries from any location without special software
Some of the drawbacks are:
- Hard to edit old posts
- To make HTML blog entries I'd need to use a HTML compatible mail client -- which I won't. Long live mutt.
I'm sure there are other benefits and drawbacks that I've yet to identify. I'll mention them as I find them.
Comments
Hallo - Could you share your mhonarc resource file and any other tools you used to make this system?
Thanks -- Sean Roberts
I've attached a tarball containing all the files related to the unblog. You'll notice the add.sh script is effectively short circuited because incremental message adding wasn't working for reasons I never documented well. In fact, there's no real documentation at all, but most of it is pretty straight forward. I'm running with MHonArch v2.6.2.
Thanks.
I am working with a group of friends to maintain a non-profits computer systems. Only problem is that half the team is non-technical, and the other half is "Microsoft Technical" (if you get what I mean).
We currently use a mailing list to communicate, it works wonderfully.
Now I need some way to track all of our work (to keep documentation up-to-date). I want a simple log (or blog) of work, but it must be seemless to add to (no one likes documenting). Can't be ugly and have sucky threading, like mailmans default archives. So a mail list based blog that doesn't require any special marking up of the email to get it into the blog. Oh, and no need to setup a "new post notifier", mailman already does that.
Now off to defeat the evil '.doc' attachment they love to send.
Thanks -- Sean Roberts
I noticed that you only use "Subject" as a reference for comments. Why not use "In-Reply-To" or "References" ? Let me guess... most junk emailers fail to properly use those headers.
I will take idea's from your work and add some other things I have thought of. Like a recent comments sidebar. That would just be a date order listing of posts that aren't in reply to anything, or I could slack and just have the most recent posts by date.
I am still shocked that a full fledged journal/weblog hasn't been built around mailing lists rather than web or blogger API input.
-- Sean Roberts
In-Reply-To and Referenced are used. In fact, they're the only thing that get message firmly linked in the Thread index (https://ry4an.org/unblog/threads.html). Notice how your messages are below the '<possible follow-ups>' marker. That indicates the Subject line indicates they're probably replies, but that no In-Reply-To or Referenced headers were found to link it conclusively with the original. You seem to be using squirrel mail and at least the message to which I'm currently replying is missing them.
> I will take idea's from your work and add some other things I have > thought of. Like a recent comments sidebar. That would just be a date > order listing of posts that aren't in reply to anything, or I could > slack and just have the most recent posts by date. > > I am still shocked that a full fledged journal/weblog hasn't been > built around mailing lists rather than web or blogger API input.
Yeah, I don't get it either. Most of the modern blogging software includes email -> post gateways, but there's no similar accomodation for comments. I'm actually beginning to suspect the Usenet-style NNTP might be the perfect marriage of posting, coments, archiving, reading, etc.
-- Ry4an
I was referring to how your "Post a Comment" are controlled. Just the "Subject". e.g.
<code> <a href="mailto:unblog@ry4an.org?subject=Re: Diplomacy at Sea and a Templated Evolver">Post a Comment</a> </code>
-- Sean Roberts
Ahh, If the mailto: protocol supported setting the In-Reply to and References: header I'd definitely use it to set them in the replies. Then then comments would be better attached. As it is, only people who reply to the actual messages on the email list end up with their comments being firmly attached (as opposed to "possibly" attached). Unfortunately, there isn't a mailer I know of that'll let you set anything but the subject and body in mailto: links.
--Ry4an
Tags
- funny
- java
- people
- python
- mongodb
- scala
- perl
- meta
- mercurial
- home
- security
- ideas-built
- ideas-unbuilt
- software
Contact
Content License

This work is licensed under a
Creative Commons Attribution-NonCommercial 3.0 Generic License.