Tag: ideas-unbuilt (Atom feed)
Wiki History Overlay
Wikis, like ry4an.org, are websites meant to be easily edited. One simply clicks the edit button, changes the content, and poof the page is changed. One of the most famous wikis is Wikipedia, the free encyclopedia. It's a wonderful resource and chocked full of information. Unfortunately, due to its anyone-can-change-it-at-any-time freedom, some folks are hesitant to consider it a reliable reference.
Wikipedia's documented accuracy is largely due to careful edit policing by interested persons. I could go change the date of Abraham Lincoln's birthday right now, but someone monitoring the changes would detect the "vandalism" and revert the change in minutes. Sadly, anyone viewing the Abraham_Lincoln page between my edit and the repair would see the wrong birthday.
Wikis also have great history features. One can look at every old version of every page, and can see the when, what, and who for every change. That's usually enough to identify intentional vandalism. The history information, however, isn't presented with the article -- it's on a separate page. It's easily available but it's not presented with the primary content.
If, instead, the primary page text were altered to indicate where recent edits were made that data could be identified as suspect and the rest could be assumed to be well vetted. I've done a mock-up of such a display below:
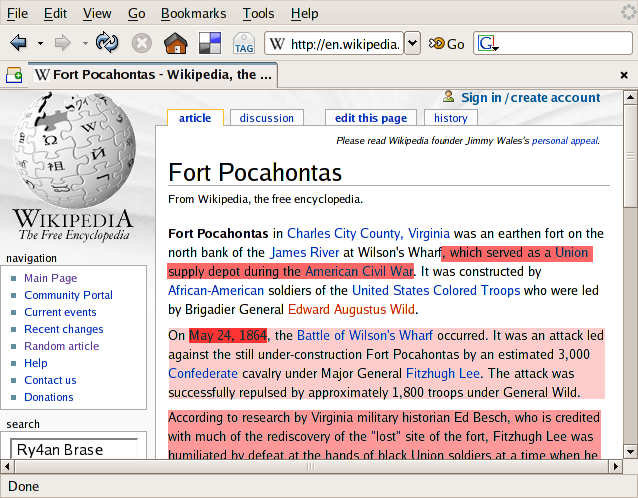
Using text background colors closer to full red to indicate new data, we can see the year has been very recently changed, a phrase in paragraph one 2nd most recently, and that the last two paragraphs were added individually and in reverse order.
There are a variety of schemes one could use to color text, including:
- last three edits
- only edits made in the last week
- all edits colored by calendar age
- all edits colored by number of subsequent edits
What's more, the history information could be placed around the edit portions using CSS span tags, allowing the color rendering mode to be toggled or entirely disabled by the reader while viewing.
The CPU usage required to generate the history spans over the document may be quite intensive, especially, if more than just the last few edits are included. Pre-caching and other web trickery would help. One could even make an external viewer or perhaps even a greasemonkey script to insert the spans without burdening the wiki's server as much. External solutions for Wikipedia could use the database dumps.
Somewhat related: Some folks at IBM did a very cool project wherein they generated activity graphs for Wikipedia pages, but again that's on a separate page from the article, not embedded within it. It does, though, produce some pretty pictures.
{kind=link}
Novelty Keg Scale
At the haloween party we got a keg of New Castle, but most folks went for the mixed drinks or the bottled beer. We kept trying to steer folks toward the keg, but it's hard to get people behind a project that's not providing good status reports.
That got me thinking that one could make a simple scale showing a gas-tank style empty to full scale for a keg of liquid. Googling for keg scale turned up some products for bar owners, but nothing consumer focused:

If instead you could start with a mechanism similar to that found in these scales:

you could provide interchangeable faceplaces for the standard keg gross and tare weights.
People rally around steadily progressing meters -- ask anyone who's been involved with a funraiser/telethon. I suspect produced cheeply enough something like this will sell to frats and the like.
Timed Home Phone Ringers
I really need to sleep in once a week, and I actually get to once a month. When I do sleep in I want the ringers off on all the phones in the house, but that's three phones to go find and then to remember to un-silence in the "morning". This past weekend I figured out that by using the call-forwarding feature on my home phone line to route all calls to my cell phone I can keep all the extensions from ringing. What's more by using the timed profiles feature on my cell phone I can have it muted until a pre-set time (say, 2pm) at which time the ringer re-enables itself. Finally I've got a good way to sleep in uninterrupted without forgetting to turn the ringers back on for the next three days.
Comments
Alternatively, you could ditch your land line. That worked for me. --Greg
Yeah, I've considered that but I like having a phone number I can give out to people whom I don't want reaching me on my cell phone -- especially since I work from home. Indeed, that's why I got the call-forwarding initially.
Netflix Self Annotations
I'm a happy Netflix user. Before I used Netflix I used to maintain a list of movies I wanted to see. Now I just use my Netflix queue for the same purpose. The only problem with my new system is by the time a recommended movie goes from the back of the queue to the front, about a year, I've long since forgotten who recommended it.
If Netflix offered a way for me to put a little note next to my own queue entries, I'd better be able to track who recommended movies or just why they made it on to my queue in the first place. Netflix does offer a feature they call their two cents system wherein you can write reviews of movies, which other members on your friends list can view. That's not really what I'm looking for though. I just want some space I can make notes to myself -- not for others.
I've suggested this to Netflix, but I've never received a reponse to a suggestion sent to them, so I'm not holding my breath.
P.S. If you're the person who recommended The Apostle to me, I now hate you.
Poker Timer DVD
There's a ton of poker time software out there and even some nifty looking dedicated hardware. At the games I attend we'll usually use a computer for the timing, but often there isn't one in the room and no one wants to bring over a laptop. However, there is almost always a TV with DVD player in whatever room gets temporarily re-purposed as the game room.
That got me thinking that a DVD that could serve as a poker timer would work in all the rooms in which we play poker and would offer these other benefits:
- large display
- easily paused using a remote
- doesn't require a computer
- simple operation
- audible alert when the blinds increase
- cheap to produce
Tournaments often last four hours or more, but a DVD can hold that much video using a variable bit rate encoding so long as the image doesn't change a great deal, and a simple count-down timer image wouldn't change very much at all.
The elapsed time per round, round number, and time remaining in the round would all be numbers on the video display, but the actual blind values, which tend to differ from tournament to tournament, would be best contained in the closed captioning track.
DVDs can contain zero or more closed captioning tracks each of which contain screen location information and text which is overlaid on the video. Putting different blind levels on different tracks allows the tournament director to easily adjust the blinds to whatever he or she prefers.
Creating the DVD would be a simple matter of transcoding computer output into a variable bit rate DVD-ready video stream. The computer output time display could be easily created using simple computer graphics programming, flash, or even javascript and HTML.
I suspect if someone took the time to put together such a DVD it could be sold in poker stores, game stores, and online for way more than the less-than-a-dollar production cost. Go do it, and I'll buy one.
Comments
It looks like someone did start making something like this (before I posted). Their implementation looks very nice: http://www.homeseriespoker.com -- Ry4an
Ringback Tones Made Less Evil
Foreign cell phone services have had a feature for awhile called Ringback Tones which allows you replace the normal ringing sound that callers hear while they're waiting for you to answer with a short audio clip. This isn't the annoying ring that the people near you hear until you answer your phone, but the even more annoying ring that the people calling you will hear directly in their ear. The feature has come to the US recently, and my cell phone provider, T-Mobile, calls its offering Caller Tunes.
When I first heard about this impending nightmare my initial thought was, "Anyone I call with this feature will have their number removed from my phone immediately." I'm still dreading calling a (soon to be former) friend and hearing the sort of music that sends me diving for a stereo's power cord, but now that I look into the feature more I'm thinking of getting it myself.
As I've discovered from T-Mobile's on-line flash demo you can actually overlay your voice atop whichever audio clip is playing as a ringback. Assuming they have a reasonably normal ringing sound as one of the clips I could select that and overlay it with my voice explaining to people that in lieu of a phone call I'd much rather get an email or a text message. Now that, would be great. Additionally, caller tunes allows you to set different ringbacks for different times of day and for different callers, which would allow me to omit the snarky message during work hours and for callers whom I know will never text anyone (Hi, mom).
It's still probably not worth doing, but damn is it tempting.
Designing a Beer Temperature Experiment
I've repeatedly encountered the statement, always presented as fact, that if you chill beer, let it return to room temperature, and then chill it again you will have affected in it a degradation of quality. This has always seemed like nonsense to me for a few different reasons, chief among them that surely this chill/warm cycle happened repeatedly during transport and retail.
As a beer snob, I generally drink beers imported from Europe. These are shipped to the US in huge container ships across the icy North Atlantic. They're then shipped in semi trucks to Minnesota. Next they're stored at distribution centers, in retail warehouses, and on the sales floor (or in the beer cooler) Surely in one season or another the temperature variance during those many legs and stops constitutes at least one cooling/warming cycle.
I'd like to test the theory, but I'm still trying to figure out just how to organize the experiment. Some things I know that have to be included or controlled are:
- temperature
- four "life cycles"
- bought cold (and kept that way)
- bought warm and cooled once
- bought cold, then warmed, and then cooled
- bought warm, cooled, warmed, and re-cooled
- all must be served at the same final temperature
- tasters
- can't know which is which in advance
- don't need to know or like beer
- beer variety:
- type
- ale
- lager
- pilsner
- stout
- location of origin
- imported
- domestic (coastal)
- domestic (local)
What I'm up in the air about is exactly how to have the tasters provide their data. Giving them identical beers which have gone through each of the four life cycles and asking them to rate them one through ten would be just about the worst way possible. That's just inviting people to rate and invent differences when the goal is to determine if there's a difference at all. Of course, even with that terrible mechanism enough repetitions would weed that sort of noise out of the data, but who has that much time.
Currently I'm leaning toward a construct wherein tasters are given two small cups of beer and are simply asked if they're the same or different. Percentage correct on a simple binary test like that would lead itself well to easy statistical analysis. Making it double-blind random and other procedural niceties could be done easily using only two testers. There should be no problem finding ample tasters.
What are the things I'm not considering?
Comments Some disussion from IRC:
<Joe> ry4an: thoughts on your beer experiment: is it you intention to test each beer variety one at a time, or mix 'n match? <Joe> seems to me that you'd get better data on the effects of temperature change by testing them one at a time <Joe> also you should test them kind of like an eye doctor tests lenses: A or B? ok now B or C? ok now C or D? and so on <Joe> the tasters should be posed this question: "can you determine a difference between these two samples? If so which one tastes 'fresher'?" <Ry4an> Joe: definitely one variety at a time. ANd I agree it's a two at a time test <Ry4an> I won't, however, be asking about fresher even. <Ry4an> that just adds unneeded data -- I jsut wantt "Different or not" <Ry4an> and 1/2 of the tests will likely be with the same beer in both cups
More talk later:
<Vane> ry4an: you should give them three small cups of beer <Vane> ry4an: one original, one heated & cooled, and one a completely different beer :) <Vane> ry4an: ask them to compare all three and rate how close they are to each other <Ry4an> vane: I don't think that's sound. People innately want to rate, but it doesn't give good data. <Louis> I like the better/worse/same approach <Ry4an> enough tests of rating woudl overcome the invented differenced people create, but I think I can get better accuracy in fewer tests if I don't invite in the imagined rating/ranking directly <Ry4an> better/worse is not the question to ask. people invent differences when ranking that they don't when answering booleans <Ry4an> ranking gets you more data but it's got more "noise" <Louis> hmm, isn't better/worse a boolean? 1 = better, 0 = worse... <Louis> I may have to re-read the test again though <Louis> the details are fuzzy at best <Ry4an> Louis: no, and that pefectly highlyts the problem. it's better/worse/same, but no one ever says 'same' because their brain demands a difference <Ry4an> and when the whole point of the test is "does it make a difference" the same is *more* important than better/worse but when you ask better/worse/same no one considers same equally <Vane> ry4an: i just think you should have a 'control' beer that is obviously different <Vane> ry4an: i guess not obviously, but different <Ry4an> vane: the control is that 1/2 of all the tests will be w/ identical beer <Ry4an> 'identical' is the only absolute one can find with which to control <Ry4an> different has an unquantifiable magnitude and thus isn't really a control <Vane> ry4an: you can do 'identical' and not 'identical' as control <Ry4an> vane: identical is the control, and different is the variable <Ry4an> For example w/ heating cycle A, B, C, and D. YOu might have tests like AA, AB, AA, AC, AD, AA <Ry4an> and you expect to hear 'same' the majority of the time on the AA pairing as your control and you compare that to how many times you hear same on the AB, AC, AD tests <Vane> you are really testing human perception, the control would be to verify human can actualy tell whether something is identical or not identical <Ry4an> vane: that's exactly what I'm saying (and you're not suggesting w/ your grossly different beer as "control") <Vane> if they can 90% of the time, then you can be assured that 90% your results with the real test is accurate <Ry4an> right, so for your control you need actual identical because it's the only absolute you have in a non-quantifiable test <Vane> not-identical is an absolute <Vane> if someone thinks all beer tastes the same, they just might always vote identical <Ry4an> but it's not really. even identical isn't perfectly absolute but it's the closest you can get <Ry4an> testing A vs A *no one* should be able to find a difference and if they do you know it's ivented <Vane> i for one, wouldn't be a good person to take the test, because I am not a beer conniseur <Ry4an> testing A vs Z you have no way of knowing what spercentage of the popular should be able to detect that difference, but you can't assume it's 100% even if Z is motor oil <Vane> i might just say they are close enough... <Ry4an> vane: actually I think non beer drinkers would be better <Ry4an> "close enough" is the sort of inexactness you're trying to eliminate in a test -- you don't invite it in by using a control that relies on "different enough" <Vane> i think non-beer drinkers would be worse, cause they wouldn't take the time necessary to savor/taste <Ry4an> that's why same/different is better than worse/better. basic pride will have even a non-beer drinker trying to be the person who most often got 'same' right on the controls whether they like beer or not <Ry4an> I suspect that Louis (a beer hater) will try very hard to guess which times he's <Ry4an> got identical peers even if it means f <Louis> ah, yeah same/diff that's right <Louis> I don't hate beer, I just can't stand the taste of the vile liquid <Ry4an> heh <Vane> so basically shad would always vote they were the same, because they are all vile
Later yet Jenni Momsen and I exchanged some emails on the subject:
On Wed, Mar 02, 2005 at 02:47:32PM -0500, Jennifer Momsen wrote: > > On Mar 2, 2005, at 2:08 PM, Ry4an Brase wrote: > > > On Wed, Mar 02, 2005 at 01:48:49PM -0500, Jennifer Momsen wrote: > > > I read your experimental set-up a while back, and forgot to tell > > > you what I thought. Namely, I think you will find your hypothesis > > > (it's not a theory, yet) not supported by your experiment. > > > Temperature is probably critical to beer quality (I'm thinking of > > > the ideal gas law, here - Eric has some other ideas as to why > > > temperature is probably important). In any case, your experimental > > > design could be improved. > > > > They're all to be served at the same temperature, it's just > > temperatures through which they pass that I'm wondering about. > > What's more, what I'm really wondering is if the temperatures > > through which they pass after I purchase them matter given all the > > temperatures through which they likely passed before I got a crack > > at them. I agree it's possible that keeping it within a certain > > temperature range for all of its life may yield a better drinking > > beer, but I also suspect that what damage can be done has already > > been done during shipping. > > Yes, this was clear. I think temperature is of such importance that > when shipping, manufacturers DO pay attention to temperature. But hey, > I'm an optimist. I suspect the origin and destination are probably promised some form of temperature control, but I suspect in actuality so long as the beer doesn't freeze and explode the shipper doesn't care a whit. > > > 1. By having a binary choice, you leave your experiment open to > > > inconsistencies in rating one beer over another. > > > > Explain. I'd never be having someone compare two different beers, > > just two like beers with different temperature life-cycles. > > Right. But, what happens when 1a does not repeatedly = 1b for a > particular taster? It's the extent of the repeatability that I want to know. If the testers are right 50% of the time then I'll have to say it makes no difference. If they're right a statistically significant percentage of the time greater than 50, then it apparently does makes a difference. > > > 2. Tasters will probably say different more times than not - an > > > inherent testing bias (i.e. if this is a test, they must be > > > different). > > > > I was thinking of telling them in advance that 50% of the time > > they'll be the same, but I don't know if that's good or bad policy. > > I think that's called bias. Bias is always bad. However, a clear > statement of the possible treatments they could encounter should > alleviate this. But it's still a form of bias that must be > acknowledged. Definitely. I just think you're exactly right that with no prior information people would say 'different' more often than they say 'same', and I was trying to come up with some way to curb that in general without affecting any one trial more than any other. > > > 3. Reconsider having tasters rate the beer on a series of qualities > > > (color, bitterness, smoothness, etc). This helps to avoid #1 and 2 > > > above, and provides more information for your experiment. This is > > > what's typically done in taste tests (for example, a recent bitterness > > > study first grouped tasters into 3 groups (super tasters, tasters, > > > non-tasters) and then had us rate several characteristics of the food, > > > not just: is the bitterness between these two samples the same?) > > > > I don't see how that improves either. I'm the first to admit I > > don't know shit about putting this sort of thing together, but I > > don't want data on color, bitterness, smoothness, etc. I understand > > that if temperature life-cycle really does make no difference then > > all that data will, with enough samples, be expected to match up, > > but if I'm not interested in the nature or magnitude of the > > differences -- only if one exists at all -- why collect it and > > inject more noise? > > You are right, this does add more data. It doesn't necessarily add > noise (well, yes it does, when you go from a binary system to a scaling > system). I know you don't want data on these factors, you just want to > know whether temperature makes for different beers. But as a scientist, > I always want to design experiments that can do more than just discover > if variable X really matters. I'm interested in bigger pictures. So > yes, you can use a simple design to discover if temperature makes for > different beers, but in the end you are unable to answer the ubiquitous > scientific question: So what? Right, whereas all I want to get from this is the ability to at a party say (in a snooty voice), "Actually, you're wrong; it doesn't matter at all." if indeed that's the case. What's more, I know whatever small amount of statistical knowledge I once had has atrophied to the point where I can barely determine "statistically significant" for a given number of trials with an expected no-correlation probability of 0.5, and I know I couldn't handle much more than that analysis-wise without pestering people or re-reading books I didn't like the first time. > > > Eric's boss started life selling equipment to beer makers in > > > England. I will nag Eric to ask him about the temperature issues. > > > > Excellent, thanks. I think that transportation period is the real > > culprit. I don't doubt they're _very_ careful about temperature > > during the brewing, but I can't imagine the trans-Atlantic cargo > > people care much at all. I know there exist recording devices which > > can be included in shipments which sample temperature and other > > environmental numbers and record them for later display vs. time, > > but I wouldn't imagine the beer importers use anything like that > > routinely. > > Why not? Certainly not cheap beers, but higher quality imports might, > no? Again, the optimist. And once some movers promised me that furniture would arrive undamaged due to the great care their contentious employees demonstrate...
Jenni's research turned up this reply:
Temperature, schmemperature. According to Mad Dog Dave (Eric's boss), manufacturers rarely worry about temperature, at nearly any stage of the process. From brewing to bottling, transportation to storage, they really could care less. So despite my best effort at optimisim, pessimism flattens all.
Dorm Apology Ad
On Tuesday some friends and I were talking about how we immaturely approached alcohol back in the dorms, and I was thinking it would be fun to take out a full (or half) page ad in the student paper, The Minnesota Daily, like this:
WE LIVED IN THE DORMS. WE DRANK.
WE COULDN'T HOLD OUR LIQUOR.Thank you, Resident Hall Facilities Staff, for your
service above and beyond the call of duty. We're sorry.
[ photo of 5 or 6 people standing soberly and shamefacedly above their name, which dorm they were in, and the years of residence]
I've contacted The Daily about getting a rate sheet, meanwhile there are a few questions to be answered:
Is this insulting? Funny or no, I don't want to actually insult the
fine residence hall maintenance staff.
How much would folks pay to be one of the people in the ad?
Depending on the cost of this thing I might need sponsorship from the other people in the ad.
Would you be interested in being in the ad? You could use a fake
name if that changes anything. Hell, you could sponsor someone else.
So if I could get a little feedback, it'd be great. Is this funny or just a dumb idea I should let die?
The Oldenburg
I've been rolling this one around in my head for a few years now, and I think it's finally coming closer to fruition: I'd like to start an old style social club.
In his book The Great Good Place Ray Oldenburg, Professor Emeritus at the Department of Sociology at the University of West Florida, says:
"Most needed are those 'third places' which lend a public balance to the increased privatization of home life. Third places are nothing more than informal public gathering places. The phrase 'third places' derives from considering our homes to be the 'first' places in our lives, and our work places the 'second.'"
Working from home I distinctly feel the need for at least a second place. Each day I head to the local coffee shop and drink more coffee than I should around semi-familiar faces. It's a pleasant time, but it's not community. Similarly in the evenings I frequently find myself wanting to get out of the house and amongst friends, without incurring the organizational and monetary expenses of an organized restaurant or bar outing.
I've got the notion that a semi-traditional social club might be just the thing for which I'm looking.
Before the 20th century gentlemen would belong to one or more social clubs where they would take meals, meet colleagues, enjoy a familiar and relaxed setting, and just generally escape the home. These clubs were typically men-only, though women-only clubs existed as well, and both generally discriminated against Jews and racial minorities.
In the 21st century these clubs still exist, albeit in a changed form. Membership policies are no longer (openly) discriminatory. The twin cities has two of the clubs of note: The Minneapolis Club (http://www.mplsclub.org/) and the University Club (http://www.universityclubofstpaul.com/). Both are large, opulent, and not quite what I'm looking for (not that they'd have me anyway).
Rather than a luxurious complex, I'd like to set the club up in just a room or two. Add some comfortable chairs, a liquor cabinet, a fridge, a bookshelf, a newspaper subscription, and twenty or so members and I think one could have the makings for a very pleasant place to while away evenings. A friend pointed out that this is almost exactly the sort of thing that the ACM, a student club, used to provide for us back in college but no longer can.
Funding would have to come in the form of monthly dues with a possible up-front initiation fee. Membership, governance, and policy could largely be cribbed from the charters of 19th century clubs with few modifications. Emily post even has a chapter on the subject: http://www.bartleby.com/95/30.html . Still there's a great deal of stuff that would have to be worked out amongst the charter members.
At this point I'm looking into general feasibility, possible locations, and interest level. I've set up a mailing list for anyone remotely interested to track progress and help shape the idea. It can be joined at: defunct. I've also got a survey which is open to anyone for whom the notion of a non-commercial third place resonates. It can be taken anonymously and can be found at: https://ry4an.org/oldenburg/survey/ .
None of this is exactly in line which what Ray Oldenburg is talking about. He's advocating free, public leisure spaces within walking distance whereas we're looking at a non-free, private leisure space to which some members will need to drive. Regardless, friend, neighbor, and interested party, Jamie, suggested we steal Ray Oldenburg's name for that of the club, and so far it's the best anyone's come up with, though nothing's final until the charter is signed.
If any part of this idea caught your interest please consider taking the survey. Even if you choose not to participate, your actions will help us to determine how The Oldenburg should be organized.
Filtering Mail Using Time of Day
I get a lot of email, and a good percentage of it is spam. To help filter the spam from the ham I use software called SpamAssassin (http://useast.spamassassin.org/). SpamAssassin applies hundreds of tests to each incoming email and increases or decreases the mail's spam score depending on the result. If the total spam score for a message is above a pre-set threshold (4.0 for me) it gets put aside.
No one rule is enough to get a message marked spam or ham; rather, each contributes a little to the overall determination. For example, here's the report for a piece of spam I recently received:
pts rule name description
---- ---------------------- --------------------------------------------------
1.5 SPAM_SUB_ADDRS Sent to a high spam sub address of mine
1.5 MY_SUB_ADDRS Sent to a sub address of mine
0.0 BAYES_50 BODY: Bayesian spam probability is 50 to 56%
[score: 0.5002]
0.6 HTML_FONT_INVISIBLE BODY: HTML font color is same as background
0.3 MIME_HTML_ONLY BODY: Message only has text/html MIME parts
0.1 HTML_MESSAGE BODY: HTML included in message
0.1 HTML_FONTCOLOR_UNSAFE BODY: HTML font color not in safe 6x6x6 palette
0.1 BIZ_TLD URI: Contains a URL in the BIZ top-level domain
1.1 MIME_HTML_ONLY_MULTI Multipart message only has text/html MIME parts
Various mis-uses of HTML formatting and sending to some email addresses I reserve for spam only earned that message a score of 4.3.
SpamAssassin is in common use, and its set of rules works very well. Looking at a summary of my email in the last 52 days one sees these numbers:
- Spam : 1377 (missed: 53) (0.37%)
- Virus: 207 (0.06%)
- Ham : 2162 (0.58%)
- Total: 3746
So of 1377 spam messages that came in during the 52 day span only 53 were missed by SpamAssassin -- just 3.85%. Not bad, but there's always room for improvement.
It seemd to me that the majority of the missed spam would come in overnight. In the morning I'd have plenty of ham messages and a piece or two of spam that SpamAssassin had missed sitting in my mail. I decided to track when spam came in to see if I could add a rule giving a higher spam score to messages arriving overnight.
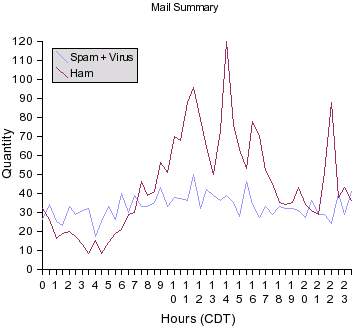
A little googling showed that others have done the same sort of tests and found that spam arrives evenly throughout the day. On The Origin of Spam has some great stats available at http://db.org/spam/. Still I gathered my own to see if they'd show the same pattern (see attached graph).
I found that spam does, indeed, favor no particular hour. However, the non-spam ham messages show pretty much the pattern you'd expect. They largely arrive while other people in my timezone are awake. So if I slip in a rule that gives some score bonus to emails arriving during off-peak hours I should see a decrease in that 3.85% error rate. I'll try it out and post the results.
Referrer-Aware, HTML-Rewriting, Caching Web Server
There are no new ideas in the message, I just don't know if the existing components have been previously combined in the way I'm proposing. If they have been I couldn't find anyone talking about it. Anyway...
Most websites live forever in obscurity getting a few hundred hits a day at best. However, if that same website gets linked to from a popular super-recommender like slashdot.org or boing-boing.net the hits can jump from 100s per days to 100s per minute. This phenomenon is called the slashdot effect (http://en.wikipedia.org/wiki/Slashdot_effect). On a server built with a low hit volume in mind it's pretty devastating, generally resulting in complete denial of service.
There are, however, things people can do to mitigate the effects of the slashdot effect -- besides buying a beefier server. One of the most effective is to take the specific page to which slashdot has posted a link and create a lighter version of it. One makes a copy with fewer images, less text, no extra boxes, headers, footers, etc. If initially the page was dynamically generated (created on the fly on a per-request basis) a static copy is made that views the same for everyone. Serving up this static, lite version imposes less CPU load on the server and reduces bandwidth consumption.
Sites that do this often configure their web servers so that visitors coming from slashdot get the lite version of the content while those coming from anywhere else get the full page as normally displayed. This is possible because all web browsers send a Referrer: header specifying from whence they just came.
Another strategy employed by many sites with non-user-specific dynamic content is the caching of dynamically generated content as static pages. These cached static pages are re-validated periodically. Doing this form of caching reduces CPU load on servers. In fact, slashdot actually caches its own front page rather than dynamically-generating it on each page view for non-logged-in users (those not viewing a personalized copy of the front page). These dynamic-as-static caches don't, however, re-write the HTML to make it lighter, thus they reduce CPU load (by generating the pages less frequently) but not bandwidth (as all the same data is transferred).
I would think that with a little configuration work, scripting, and maybe a custom Apache (web server) module one could combine and automatic referrer detection, lite version creation, and dynamic content caching to produce a site that in general usage does no caching or content-rewriting (as they're generally unnecessary for small sites), but if and only if the referrer on a request came from a super-recommender would automatically create, cache, and use a lite version of the requested content.
Setting up a referrer specific, auto-caching, auto-rewriting system like this would be better than manually creating a lite version and inserting a referrer-based redirection rule after one's been slashdotted, because the sudden and fleeting nature of a slashdotting provides no warning and ends shortly after. Heck, if the slashdotting drops one's server to its knees one might not even be able to get into it to insert the "redirect to a light version by referrer" logic manually.
If I ever get around to putting such a backup system on my web server I'll post how I ended up doing it. Then again, first I'd have to do something interesting enough to get slashdotted.
A Young Hacker's Interactive Primer
For the last five or so years I've been trying to imagine what it would have been like growing up with easy computing, and I don't think it would have been good for me. Back in 1988 when I first started seriously playing with computers they were hard to use. You had to learn a lot of obscure text commands, and most everything you tried to do required that you know how something worked that could reasonably have been abstracted away from you.
Because of that level of difficulty I think I turned out to be a much stronger computer user, programmer, and general hacker[1]. I now delve into difficult computer problems confident in the knowledge that with enough effort I'll figure out what I need to understand to make things work. I'm now quite choosy about which "ease of use" features I'll let hide ugly detail from me, and which ones I'll skip to instead reveal the underlying system.
The problem is, I was forced to climb the steep learning curve of the command line interface and other "old school" hallmarks. I don't know if I would have done it if I could have dragged myfile.txt onto a picture of printer instead of typing COPY MYFILE.TXT > LPT1
I then start to worry about the young teenagers I know who have grown up in a graphical user interface world. I don't see them embracing difficult computing and the accompanying power and flexibility. Who can blame them. It's a pain in the ass for the first few months/years and teenagers aren't always known for the determination, foresight, and patience.
In an attempt to create an inviting way to draw teens into advanced computing I've started a project called The Young Hacker's Interactive Primer (with apologies to Neal Stephenson). As I see it the two things necessary to get a kid interested in exploring difficult computing were (1) a safe place to do it and (2) inducement to further exploration.
To provide a safe place in which to explore a UNIX system, I decided the easiest was to do it was to just give them one. There are plenty of alternatives such as dual booting their existing systems, run-from-CD UNIXes, and just giving them remote shell accounts. I figured actual physical systems were the best solution because there's no risk of them trashing their parents or their real computer, they can have root when they're ready, and because everyone likes getting a gift -- even when it's a Pentium 233.
The inducement comes in the form of little puzzles and tasks of increasing difficulty. Initially you just need to log in with provided user name and password. Then you work on viewing the contents of a file. Then changing a directory. Each task can build on the previous ones while requiring one new fundamental skill be learned, ideally from man pages and documentation. In envision it as something like one of the old infocom text games except taking place right in the UNIX shell.
Who knows, maybe my attempts to make learning difficult computing will still be too boring, frustrating, and un-glamorous to draw a kid through the 10 different layers of abstraction that Apple and Microsoft want them the use unquestioningly. Worst case I get a few old computers out of my closet.
The fledgling project can be found at https://ry4an.org/primer/ There's still not much to see, but I expect to change that shortly as I've already told a kid I know that I hope to give him a computer shortly after thanksgiving.
[1] http://catb.org/~esr/jargon/html/H/hacker.html
Road Rage Races
Road Rage Races are an idea I came up with a few years back that I'm trying to resurrect. I've updated the website (https://ry4an.org/rrr), and tacked on a new tag line: "Light travels at 299,792,460 m/s. Immaturity travels at 5 mph."
In a Road Rage Race the competitors start out in a centrally located parking lot in the Twin Cities area. They then race to one of five previously agreed upon destinations selected randomly at the time of the race start. The hitch being that this is done during the height of the evening rush hour keeping top speed in the 10 to 20 mph range.
Particular fun could be had if multiple types of vehicles can be coaxed into participating. I'd love to see folks on bike vs. foot vs. car vs. bus vs. motorcycle. I tried to get one of these organized in 2001, but it's hard for everyone to get out of work early. Maybe a Friday or Saturday night in the busy downtown area would work as well.
What's nice now is that consumer grade GPS devices have come down in price significantly. Many of the people I'm trying to cajole into playing already have them. Their position tracking features will allow us to record where each car is at each second. After the race is over we'll be able to create a detailed replay with almost no effort and great accuracy.
Comments
I'd be up for it, could be a lot of fun. However, don't we all need to get hopped up little sports cars ala The fast and the Furious?
haha, just kidding about that...
-- Louis Duhon
Half Baked Ideas I've Had
Half Bakery (http://halfbakery.com) is a website where people can post poorly thought out ideas so they can be commented on, criticized, and (occasionally) praised by total (and generally snarky) strangers. It's a clique-y place that's often unkind to new arrivals, but I was lucky enough to get generally favorable reviews for a few of the ideas I've posted there. Here are a some of the entries I've created there in the past.
Locking Clothes Dryer http://www.halfbakery.com/idea/Locking_20Clothes_20Dryer
Designed to prevent laundromat theft and vandalism this idea involves a key or pin that has to be used to open the dryer after the drying cycle has started. This allows the human operator to leave the laundromat without worrying about the clothes left behind. Optionally dryers left unattended for too long could automatically unlock so rude peoples' clothes can still be dumped on the floor.
Non-Integer Page Numbers http://www.halfbakery.com/idea/non-integer_20page_20numbers
I thought this one up about ten years ago. I'd like it if books had their page numbers expressed not only as sequential integers but also as whatever fraction of the book has been read at that point. The primary benefit of this system would be making citation page numbers useful across different editions. Page 202 is very different in hardback and paperback editions, but page 34.35% is approximately the same place in both.
Secret Off-Shore Bank http://www.halfbakery.com/idea/Secret_20Offshore_20Bank
Pure silliness. I want a bank with a name more exciting that Wells Fargo. It can be based in Nebraska and be boring as hell, but so long as my checks said "Secret Off-Shore Bank" I'd be happy.
Right-Sized Serving Platter http://www.halfbakery.com/idea/Right-Sized_20Serving_20Platter
Right before the guests show up at a cocktail party the food table looks as good as its going to all night. The hors d'oeuvre platters are arranged nicely and have no gaping holes. However, ten minutes after the first hungry visitor arrives the serving platters have big gaps making the spread look a little sad. Replenishing works so long as one still has food reserves, but as the party winds down barren looking appetizer platers are almost unavoidable.
If, however, one had a serving platter whose area shrunk with the food quantity one could avoid this unsightly result. Stupid idea? Of course, that's what the half-bakery is all about.
I'm running out of old ideas to post to this list. Soon I'll have to either think of something new or shut-up, which I'm sure my one subscriber wouldn't mind. Hi Gabe.
Comments
Looks like the halfbakery suffered a catestrophic disk crash without backups this past October. My ideas are still there, but all their positive votes are gone. -- Ry4an
Text to Speech Tuning with a Polygraph
Text to speech programs do okay on words they know, but on longer words not in their 'dictionary' they have to sound them out phonetically which seems to be a really hit or miss operation. I wonder if one could hook up text to speech software and a polygraph sensor together to monitor the listeners reaction to the words being read.
I know I cringe when I hear something mis-pronounced and surely something in my mental wince is externally measurable. If the software detected a negative reaction to the way it pronounced a word it could try an alternate pronunciation the next time. Granted it would be a highly iterative process -- requiring many listeners for a each text sample so that the most-favorable response for each word can be found, but how many people listened to Harry Potter as a book on tape.
I suppose that portions of the text cause a negative response anyway (bad happenings for the protagonist, etc.) would have to be ignored or treated differently, but still maybe there's something do able there. At any rate, it has to be better than reading the whole dictionary into a computer.
Tags
- funny
- java
- people
- python
- mongodb
- scala
- perl
- meta
- mercurial
- home
- security
- ideas-built
- ideas-unbuilt
- software
Contact
Content License

This work is licensed under a
Creative Commons Attribution-NonCommercial 3.0 Generic License.