Outcome Probability for One Handed Solitaire
Back in 1994 my circle of high school friends spent a lot of time sitting around talking (there were no cell phones) and for about a week we were all playing one handed solitaire. In suburban St. Louis we called it idiot's delight solitaire (which turns out to be an entirely different game), because there is absolutely no human input after the shuffle. As soon as you've started playing it's already determined whether you've won -- you just spend five minutes learning if you did.
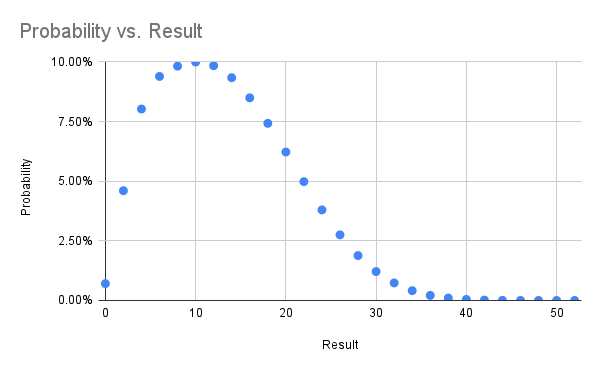
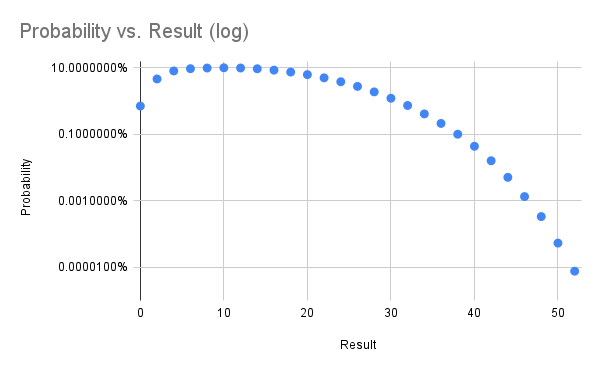
Naturally we wondered how likely our very rare wins were, and being a computer nerd back then too I wrote a Pascal(!) program to simulate the game and arrived at the conclusion you win one in every 142 games.
Now thirty years later I've taught the game to the eleven year old in our home, who is just game back from a phone-free summer camp with a deck of cards and dubious shuffling skills.
My old Pascal is lost to bitrot, but the game as python, using a sort of janky off the shelf deck_of_cards module is trivial:
def play():
deck = deck_of_cards.DeckOfCards()
hand = []
while not deck._deck_empty():
hand.append(deck.give_random_card())
while len(hand) > 3:
if hand[-1].suit == hand[-4].suit:
del hand[-3:-1]
elif hand[-1].rank == hand[-4].rank:
del hand[-4:]
else:
break
return len(hand)
On the 486 I was running at the time I recall getting ten thousand or so runs over many days. On a tiny Linode in the modern era I got 50 million runs in 15ish hours.
I've gathered the results in a spreadsheet and included some probability graphs below. In trying to find the real name of this game I came across a previous analysis from 2014 which comes to the same overall probability. That blog post is now down (hence the archive.org links) with ominous messages telling folks the author is definitely no longer thinking about this game.
A Gamebook Report with Graphviz, Google Sheets, Python, and Juypter/Colab
An 11 year old in our house needed to do a book report for school in the form of a board game and selected a gamebook, apparently the generic name for the trademarked Choose Your Own Adventure books. The non-linear narrative made the choice of board layout easy -- just use the graph of pages-transitions ("Turn to page 110").
The graphviz library is always my first choice when I want to visualize nodes and edges, and the python graphviz module provides a convenient way to get data into a renderable graph structure.
I wanted to work with the 11 year old as much as possible, so I picked a programming environment that can be used anywhere, jupyter notebooks, and we ran it in Google's free hosted version called colab.
The data entry was going to be the most time consuming part of the project, and something we wanted to be able to work on both together and apart. For that I picked a Google sheet. It gave us the right mix of ease of entry, remote collaboration, and a familiar interface. Python can read from Google sheets directly using the gspread module, saving a transcription/import step.
It took us a few weeks of evenings to enter the book's info into the data spreadsheet. The two types of data we needed were places, essentially nodes, and decisions, which are edges. For every place we recorded starting page, a description of what happens, and the page where you next make a decision or reach an ending. For every decision we recorded the page where you were deciding, a description of the choice, and the page to which you'd go next. As you can see in the data spreadsheet that was 139 places/nodes and 177 decisions/edges.
Once we'd entered all the data we were able to run a short python program to load the data from the spreadsheet, transform it into a graph object, and then render that graph as a pdf file. That we printed with a large format printer, and then the 11 year old layered on art, puzzles, rules, and everything else that turns a digraph into a playable game. The final game board is shown below, with a zoomed section in the album.
One interesting thing about this particular book that was only evident once the full graph was in front of us was that the very first choice in the book splits you into one of two trees that never reconnect. Lots of later choices in the book loop back and cross over, but that first choice splits you into one of two separate books.
I've omitted the title and author info from the book to stop this giant spoiler from showing up on google searches, but the 11 year old assures me it was a good, fun read and recommends it.

Apache To CloudFront With Lambda At Edge
I've been running my (this) vanity website and mail server on Linux machines I administer myself since 1998 or so, but it's time to rebuild the machine and hosting static HTTPS no longer makes sense in a world where GitHub or AWS can handle it flexibly and reliably for effectively free. I did want to keep running my own mail server, but centralization in email has made delivery iffy and everyone I'm communicating with is on gmail, so the data is going there anyway.
Because I've redone the ry4an.org website so many times and because cool URLs don't change I have a lot of redirects from old locations to new locations. With apache I grossly abused mod_rewrite to pattern match old URLs and transform them into new ones. No modern hosting provider is going to run apache, especially with mod_rewrite enabled, so I needed to rebuild the rules for whatever hosting option I picked.
Github.io won't do real redirects (only meta refresh tags), so that was right out. AWS's S3 lets you configure redirects using either a custom x-amz-website-redirect-location header on a placeholder object in the S3 bucket or some hoary XML routing rules at the bucket level, but neither of those allow anything more complicated than key prefix matching.
AWS's content delivery edge network, CloudFront, doesn't host content or generate redirects -- it's just a caching proxy --, but it lets you deploy javascript functions directly to the edge nodes which can modify requests and responses on their way in and out. With this Lambda at Edge capability you're restricted to specific releases of only the javascript runtime, but that's enough to get full regular expression matching with group extraction.
Ry4an in Title Case
Python has a uniquely bad title case function which turns my already silly name into Ry4An, capitalizing the 'a' because it follows a non-letter character. I can't be sure that all the bulk email I get that's sent to Ry4An Brase has passed through Python's .title() function, but I've not found another language or framework with so bad an implementation.
At least Python warns you that their version is terrible right in the docstring for title and provides a slightly better one they suggest you paste directly into your code. There are, of course, better versions available in libraries like titlecase which handle things like not capitalizing articles.
Other languages seem to avoid the fussiness of title case requirements by omitting it from the core language entirely (ruby, java), leaving it to third party implementors like rails and apache commons.

Kindle Highlights and Ratings
When reading I've always underlined sentences that make me happy. Once the kids got old enough to understand there's no email or fun on a Kindle I switched from dead tree books, and now the underlining is stored in Amazon's datacenters.
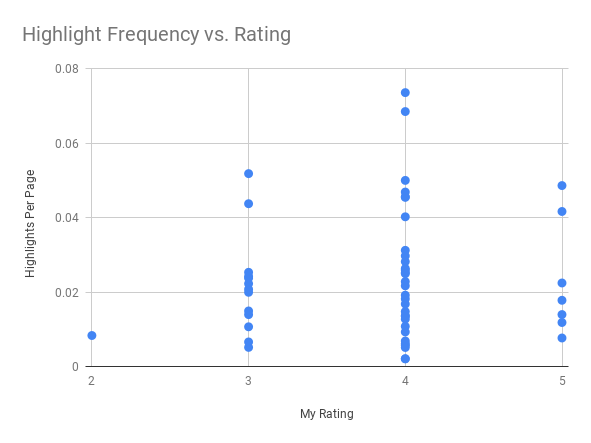
After a few years of highlighting on Kindle I started to wonder if the number of sentences that I liked and the eventual five-star scale rating I gave a book had any correlation. Amazon owns Goodreads and Kindle services sync data into Goodreads, but unfortunately highlight data isn't available through any API.
I was able to put together a little Python to scrape the highlight counts per book (yay, BeautifulSoup) and combine it with page count and rating info from the goodreads APIs. Our family scientist explained "the statistical tests to compare values of a continuous variable across levels of an ordinal variable", and there was no meaningful relationship. Still it makes a nice picture:
Home Alarm Analytics With AWS Kinesis
Home security system projects are fun because everything about them screams "1980s legacy hardware design". Nowhere else in the modern tech landscape does one program by typing in a three digit memory address and then entering byte values on a numeric keypad. There's no enter-key -- you fill the memory address. There's no display -- just eight LEDs that will show you a byte at a time, and you hope it's the address you think it is. Arduinos and the like are great for hobby fun, but these are real working systems whose core configuration you enter byte by byte.
The feature set reveals 30 years of crazy product requirements. You can just picture the well-meaning sales person who sold a non-existent feature to a huge potential customer, resulting in the boolean setting that lives at address 017 bit 4 and whose description in the manual is:
ON: The double hit feature will be enabled. Two violations of the same zone within the Cross Zone Timer will be considered a valid Police Code or Cross Zone Event. The system will report the event and log it to the event buffer. OFF: Two alarms from the same zone is not a valid Police Code or Cross Zone Event
I've built out alarm systems for three different homes now, and while occasionally frustrating it's always a satisfying project. This most recent time I wanted an event log larger than the 512 events I can view a byte at a time. The central dispatch service I use will sell me back my event log in a horrid web interface, but I wanted something programmatically accessible and ideally including constant status.
The hardware side of the solution came in the form of the Alarm Decoder from Nu Tech. It translates alarm panel keypad bus events into events on an RS-232 serial bus. That I'm feeding into a Raspberry Pi. From there the alarmdecoder package on PyPI lets me get at decoded events as Python objects. But, I wanted those in a real datastore.
Raspberry Pi UPS
I'm starting to do more on a raspberry pi I've got in the house, and I wanted it to survive short power outages. I looked at buying an off the shelf Uninteruptable Power Supply (UPS), but it just struck me as silly that I'd be using my house's 120V AC to power to fill a 12V DC battery to be run through an inverter into 120V AC again to be run through a transformer into DC yet again. When the house is out of power that seemed like a lot of waste.
A little searching turned up the PicoUPS-100 UPS controller. It seems like it's mostly used in car applications, but it has two DC inputs and one DC output and handles the charging and fast switching. The non-battery input needs to be greater than the desired 12 volts, so I ebayed a 15v power supply from an old laptop. I added a voltage regulator and buck converter to get solid 12v (router) and 5v (rpi) outputs. Then it caught on fire:

But I re-bought the charred parts, and the second time it worked just fine:

Pylint To Github
I spent a few hours trying to get the Jenkins Git & Github plugins to:
- run pylint on all remote branch heads that:
- arent' too old
- haven't already had pylint run on them
- send the repo status back to GitHub
I'm sure it's possible, but the Jenkins Git plugin doesn't like a single build to operate on multiple revisions. The repo statuses weren't posting, the wrong branches were getting built, and it was easier to write a quick script.
Now whenever someone pushes code at DramaFever pylint does its thing, and their most recent commit gets a green checkmark or a red cross. If/when they open a PR the status is already ready on the PR and warns folks not to merge it if pylint is going to fail the build. They can keep heaping on commits until the PR goes green.
I run it from Jenkins triggerd by a GitHub push hook, but it's setup so that even running it from cron on the minute is safe for those without a CI server yet.
Bitcoin Conversion In Google Spreadsheets
I've been using Charlie Lee's excellent Google Spreadsheet Bitcoin tracker sheet for awhile but it pulls data from a single exchange at a time and relies on the ordering of those exchanges on the bitcoinwatch.com site, which vary with volume.
I figured out I could get better numbers more reliably from bitcoinaverage.com, which (predictably) averages multiple exchanges over various time periods. They offer a great JSON API, but unfortunately Google spreadsheets only export JSON -- they don't have a function for importing it.
None the less I was able to fake it using a regex. You can pull the 24 hour average price in with this forumla:
=regexextract(index(importdata("https://api.bitcoinaverage.com/ticker/USD"),2,1), ": (.*),")+0
If you want that to update live (not just when you open the spreadsheet) you need to use Charlie's hack to get the sheet to think the formula depends on live stock data:
=regexextract(index(importdata("https://api.bitcoinaverage.com/ticker/USD?workaround="&INT(
NOW()*1E3)&REPT(GoogleFinance("GOOG");0)),2,1), ": (.*),")+0
I've put together a sample spreadsheet based on Charlie's.
Occuped: Twine + Go + App Engine
In our NY office We've got 40 people working in a space with two bathrooms. Walking to the bathrooms, finding them both occupied, and grabbing a snack instead is a regular occurrence. For a lark I took a Twine with the breakout board and a few magnetic switches and connected them to the over taxed bathroom doors.
The good folks at Twine will invoke a web hook on state change, so I created a tiny webapp in Go that takes the GET from Twine and stashes it in the App Engine datastore. I wrote a cheesy web front end to show the current state based on the most recent change. It also exposes a JSON API, allowing my excellent coworkers to build a native OS X menulet and a much nicer web version.

Tags
- funny
- java
- people
- python
- mongodb
- scala
- perl
- meta
- mercurial
- home
- security
- ideas-built
- ideas-unbuilt
- software
Contact
Content License

This work is licensed under a
Creative Commons Attribution-NonCommercial 3.0 Generic License.