Homemade Tonic
I just made my third batch of tonic water from Mark Sexauer's Recipe:
- 4 cups water
- 4 cups sugar
- 1/4 cup cinchona bark
- 1/4 cup citric acid
- Zest and juice of 1 lime
- Zest and juice of 1 lemon
- Zest and juice of 1 orange
- 1 teaspoon coriander seeds
- 1 teaspoon dried bitter orange peel
- 10 dashes bitters
- 1 hand crushed juniper berry (I used two)
The flavor is excellent, but the process is terrible. Specifically, filtering the cinchona bark from the mixture after extracting the quinine (actually totaquine) from it is nearly impossible. It's so finely ground it clogs any filter, be it paper or the mesh on a french press coffeemaker, almost immediately. I've tried letting it settle and pouring off the liquid, forcing the liquid through with back pressure, and letting it drip all night -- none work well. A friend using the same recipe build a homemade vacuum extractor, but I've not yet gone that far.
This time I used multiple coffee filters and gravity, changing out the filter after each few tablespoons of water flowed through and the filter was plugged. I lost about half the liquid volume in the form of discarded, soggy filters. On previous batches I didn't take the liquid loss into account when adding sugar, yielding tonic water that was too sweet -- my primary complaint with store bought tonic --, but this time I halved the sugar as well and got a nice tart result. The fresh citrus and two juniper berries I use make it a perfect match for a nice gin. I'm able to carbonate the mixture with my own carbonation rig.
For the next batch I'm going to see if I can buy some quinine from the gray market online pharmacies. A single 300mg tablet, used to fight malaria or alleviate leg cramps, will make three strong liters and I'll be able to skip the filtering process entirely. The other benefit to using quinine instead of totaquine is aesthetic. The cinchona bark leaves my homemade tonic syrup brown and the water an unpleasant yellow color as you can see below.

A Few Quick EC2 Security Group Migration Tools
Like half the internet I'm working on duplicating a setup from one Amazon EC2 availability zone to another. I couldn't find a quick way to do that if my stuff wasn't already described in Cloud Formation templates, so I put together a script that queries the security groups using ec2-describe-group and produces a shell script that re-creates them in a different region.
If all your ec2 command line tools and environment variables are set you can mirror us-east-1 to us-west-1 using:
ec2-describe-group | ./create-firewall-script.pl > create-firewall.sh ./create-firewall.sh
With non-demo security group data I ran into some group-to-group access grants whose purpose wasn't immediately obvious, so I put together a second script using graphviz to show the ALLOWs. A directed edge can be read as "can access".
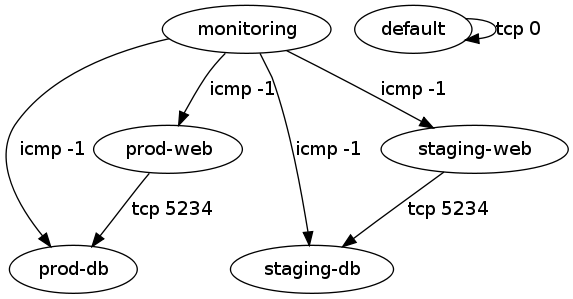
That script can also be invoked as:
ec2-describe-group | ./visualize-security-groups.pl > groups.png
The labels on the edges can be made more detailed, but having each of tcp, udp, and icmp shown started to get excessive.
Both scripts and sample input and output are in the provided tarball.
Using the Khan Academy to Vet Online Panhandlers
I'm a huge fan of the Khan Academy (and if you haven't yet watched Salman's presentation at TED2011 you should go do that). I'm involved (slightly) in an effort to bring Khan Academy instruction to a local school district and have a standing offer to "coach" participants. Today, though, I found a use for the Khan Academy site probably doesn't endorse: dealing with online panhandlers.
Before today I'd never seen an IRC panhandler, email sure, but never IRC. This morning, though, someone wandered into #mercurial asking for money to renew a domain. Most people ignored the request since it's grossly inappropriate in a software development work space, but I offered the kid the money if he'd do algebra problems on the Khan Academy site.
We dropped into a private chat and with a mixture of whining and negotiation struck upon a deal wherein he'd do some math and I'd paypal him a few bucks. The whole exchange was silly and I got nothing out of it except a blog entry, but the math did serve some small purpose: it made sure the exchange took time and attention for long enough to not be something that the kid could be simultaneously working in multiple other channels at the same time. Also who doesn't need to known mean, median, and mode.
The Khan Academy coach interface provided me real-time feedback on the problems, including seconds spent on each, what they were, and how he answered. He might have been plugging them into Wolfram Alpha or asking in another IRC channel, but I didn't get that sense, and the time consumed would be the same either way.
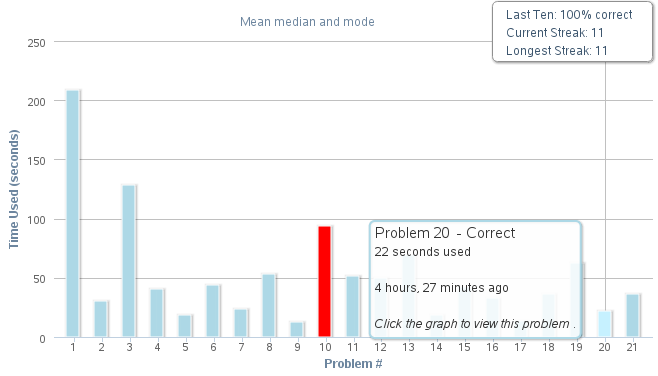
Surprisingly, further chat proved out the details in the initial pitch. The domain is now registered through 2014 and hosts a nice blog. Whois info, blog identity, and paypal address all align with a Florida teen. Not that I would have cared if it was a gold farmer in China -- though their thirteen year olds can do algebra.
Other kids: For the record, I'm not interesting in giving you money for math, or anything else, but if you add ry4an at brase.com as a coach on Khan Academy I'm happy to help with math.
Below are some of the choice parts from the full chat transcript:
reStructuredText Resume
I've had a resume in active maintenance since the mid 90s, and it's gone through many iterations. I started with a Word document (I didn't know any better). In the late 90s I moved to parallel Word, text, and HTML versions, all maintained separately, which drifted out of sync horribly. In 2010 I redid it in Google Docs using a template I found whose HTML hinted at a previous life in Word for OS X. That template had all sorts of class and style stuff in it that Google Docs couldn't actually edit/create, so I was back to hand-editing HTML and then using Google Docs to create a PDF version. I still had to keep the text version current separately, but at least I'd decided I didn't want any job that wanted a Word version.
When I decided to finally add my current job to my resume, even months after starting, I went for another overhaul. The goal was to have a single input file whose output provided HTML, text, and PDF representations. As I saw it that made the options: LaTeX, reStructuredText, or HTML.
I started down the road with LaTeX, and found some great templates, articles, and prior examples, but it felt like I was fighting with the tool to get acceptable output, and nothing was coming together on the plain text renderer front.
Next I turned to reStructuredText, and found it yielded a workable system. I started with Guillaume ChéreAu's blog post and template and used the regular docutils tool rst2html to generate the HTML versions. The normal route for turning reStructuredText into PDF using doctools passes through LaTeX, but I didn't want to go that route, so I used rst2pdf, which gets there directly. I counted the reStructuredText version as close-enough to text for that format.
Since now I was dealing entirely with a source file that compiled to generated outputs it only made sense to use a Makefile and keep everything in a Mercurial repository. That gives me the ability to easily track changes and to merge across multiple versions (different objectives) should the need arise. With the Makefile and Mercurial in place I was able to add an automated version string/link to the resume so I can tell from a print out which version someone lis looking at. Since I've always used a source control repository for the HTML version it's possible to compare revisions back to 2001, which get pretty silly.
I'm also proud to say that the URL for my resume hasn't changed since 1996, so any printed version ever includes a link to the most current one. Here are links to each of those formats: HTML, PDF, text, and repository, where the text version is the one from which the others are created.
Trying Hirelite
Tonight I tried Hirelite, and I really think they're on to something. They arrange online software developer interview speed-dating-style events where N companies and N software developers each sit in in front of their own webcams and are connected together for live video chats five minutes at a time. It's like chatroulette with more hiring talk and less genitalia.
They pre-screen the developers to make sure they're at least able to solve a simple programming problem and screen the companies by charging them a little money. Each session has a theme, like "backend developers", and a geographic region associated with it. After each five minute interview -- there's a countdown timer at the top -- each party indicates with a click whether or not they'd like to talk further. Mutual matches get one another's contact information immediately afterward.
Observations
I've only tried Hirelite once, which was only nine interviews, but from my limited experience here are some of my observations:
- No one is ready for an interview-like talk that lasts only five minutes. One party or another launches into a sales pitch and uses up two or three minutes right off the bat, leaving little time for a more bidirectional exchange.
- When it's clearly a bad skills/interests match, five minutes is still easy to fill. If two people can't find something, anything to talk about for five minutes something is wrong with one or both of them.
- With only five minutes it's less like an interview, or even a phone pre-screen, and more like a hand-delivery of a resume.
- Race and gender aren't always knowable from a resume, but they immediately are when a video chat happens this early in the process. Conceivably there could be some EoE considerations there, be they concious or not.
- The novelty of what everyone is doing was enough to keep things light. One of my interviews started with an interviewer holding up a sheet of paper that said "USE TEXT CHAT" where he explained his mic wasn't working. How everyone dealt with the technical glitches is probably as good an indicator of personality as anything else -- I did an entire exchange using text-chat and pantomime.
Tips for Participants
Again, I've only done this once, but here are some tips I intend to employ if I try this again:
- Make sure to wear headphones -- without them you'll echo.
- If you're using a laptop have an external keyboard plugged in -- you don't want to have to hunch forward to use the one on your laptop if it comes to text chat.
- Interviewees: Make sure to include a resume link in your pre-interview profile. Most interviewers had looked at mine, and the rest did so during the chat.
- Check your lighting before starting. I looked like I was sitting in a cave.
Technical Issues
I'm sufficiently enamored with the system that the technical glitches were more funny than they were frustrating, but I could easily see someone else feeling otherwise. Here's what I encountered.
Before the session began I followed Hirelite's advice to test my "video and audio" with their test interview link. My camera worked fine -- I could see myself -- but I couldn't hear myself on audio. I spoke to Hirelite about that, and it turns out you're not supposed to hear yourself during the test -- there is no test for audio.
I tried both Google Chrome on Linux and Firefox on Linux with the test, and both worked. It wasn't until my audio stopped working well during an interview that I realized the text chat wasn't working in Chrome -- the text entry box was cutoff on my small netbook screen. A quick switch to Firefox got that going.
The most persistent technical problem I had was the lagging of my outbound audio. I could generally see and hear the interviewer with little lag and in synch, and my interviewer and I could both see my video unlagged, but my audio was delayed by about 40 seconds starting about the sixth interview. This made speaking all but impossible.
My internet connection speed just tested out at 14Mbps downstream and 5Mbps upstream which is more than sufficient for small video and low bitrate audio, so I don't think the problems were with my bandwidth. What's more, since Hirelite is built in Flash (who does that this decade?!) likely using RTFMP (I'm kicking myself for not running Wireshark during the session) audio and video are multiplexed in the same packet stream -- so any de-synch-ing of the two is almost certainly a software problem not a network problem.
When things were glitching I was often able to improve them temporarily by reloading the page. This kills off the Flash component and reloads it, which brought the lag down for awhile. The Hirelite system was able to re-connect me to my in-progress session with nary a hiccup, which is a nice touch. I was afraid it would automatically move me to the next interviewer.
All in all a great idea. StackExchange should buy Hirelite using some the 12 million they just raised, hopefully some of the money from their snack room.
{kind=link}
Automatic SSH Tunnel Home As Securely As I Can
After watching a video from Defcon 18 and seeing a tweet from Steve Losh I decided to finally set up an automatic SSH tunnel from my home server to my traveling machines. The idea being that if I leave the machine somewhere or it's taken I can get in remotely and wipe it or take photos with the camera. There are plenty of commercial software packages that will do something like this for Windows, Mac, and Linux, and the highly-regarded, open-source prey, but they all either rely on 3rd party service or have a lot more than a simple back-tunnel.
I was able to cobble together an automatic back-connect from laptop to server using standard tools and a lot of careful configuration. Here's my write up, mostly so I can do it again the next time I get a new laptop.
BoingBoing Posts in Rogue
Previously I mentioned I was importing the full corpus of BoingBoing posts into MonogoDB, which went off without a hitch. The import was just to provide a decent dataset for trying out Rogue, the Mongo searching DSL from the folks at Foursquare. Last weekend I was in New York for the Northeast Scala Symposium and the Foursquare Hackathon, so I took the opportunity finish up the query part while I had their developers around to answer questions.
Loading BoingBoing into MongoDB with Scala
I want to play around with Rogue by the Foursquare folks, but first I needed a decent sized collections of items in a MongoDB. I recalled that BoingBoing had just released all their posts in a single file, so I downloaded that and put together a little Scala to convert from XML to JSON. The built-in XML support in Scala and the excellent lift-json DSL turned the whole thing into no work at all:
Traffic Analysis In Perl and Scala
I needed to implement the algorithm in Practical Traffic Analysis Extending and Resisting Statistical Disclosure in a hurry, so I turned to my old friend Perl. Later, when time permitted I re-did it in my new favorite language, Scala. Here's a quick look at how a few different pieces of the implementation differed in the two languages -- and really how idiomatic Perl and idiomatic Scala can look pretty similar when one gets past syntax.
Syntax Highlighting and Formulas for Blohg
I'm thus far thrilled with blohg as a blogging platform. I've got a large post I'm finishing up now with quite a few snippets of source code in two different programming languages. I was hoping to use the excellent SyntaxHighlighter javascript library to prettify those snippets, and was surprised to find that docutils reStructuredText doesn't yet do that (though some other implementations do).
Fortunately, adding new rendering directives to reStructuredText is incredibly easy. I was able to add support for a .. code mode with just this little bit of Python:
Tags
- funny
- java
- people
- python
- mongodb
- scala
- perl
- meta
- mercurial
- home
- security
- ideas-built
- ideas-unbuilt
- software
Contact
Content License

This work is licensed under a
Creative Commons Attribution-NonCommercial 3.0 Generic License.