Tag: meta (Atom feed)
Apache To CloudFront With Lambda At Edge
I've been running my (this) vanity website and mail server on Linux machines I administer myself since 1998 or so, but it's time to rebuild the machine and hosting static HTTPS no longer makes sense in a world where GitHub or AWS can handle it flexibly and reliably for effectively free. I did want to keep running my own mail server, but centralization in email has made delivery iffy and everyone I'm communicating with is on gmail, so the data is going there anyway.
Because I've redone the ry4an.org website so many times and because cool URLs don't change I have a lot of redirects from old locations to new locations. With apache I grossly abused mod_rewrite to pattern match old URLs and transform them into new ones. No modern hosting provider is going to run apache, especially with mod_rewrite enabled, so I needed to rebuild the rules for whatever hosting option I picked.
Github.io won't do real redirects (only meta refresh tags), so that was right out. AWS's S3 lets you configure redirects using either a custom x-amz-website-redirect-location header on a placeholder object in the S3 bucket or some hoary XML routing rules at the bucket level, but neither of those allow anything more complicated than key prefix matching.
AWS's content delivery edge network, CloudFront, doesn't host content or generate redirects -- it's just a caching proxy --, but it lets you deploy javascript functions directly to the edge nodes which can modify requests and responses on their way in and out. With this Lambda at Edge capability you're restricted to specific releases of only the javascript runtime, but that's enough to get full regular expression matching with group extraction.
Eulogy For a Good Server
Two days ago I powered down a good server for the first time in years and the last time ever. It doesn't compare to euthanizing a pet, but it still made me more sad than I expected. Below is a remembrance. I've made the server male because once you've gotten so silly as to write a eulogy for a server you might as well go all out.
Ry4an.org II was a good server. In 2001 his Pentium III hardware was already old -- corporate castoff acquired for free. He took a Fedora install without any configuration hassles and always assigned the same ethX numbers to each of his three PCI NICs, without aliases in the modules.conf, which Ry4an.org I could never get right.
Ry4an.org II ran headless in dusty, cat-fur-filled environs for ten years without ever experiencing a hardware failure of any sort. At age five he moved from a hot closet to a cool basement with less reliable power. He never got the UPS I promised him.
He ran Postfix and Apache for tens of domains. He ran MySQL for Bugzilla and Gallery. He ran dhcpd for both internal and dmz network segments with his iptables keeping them properly isolated. He routed packets to and from a business class connection with the world. He handled two boingboing-ings with aplomb. My mutt and irssi screen sessions never died. He earned his static IP.
When his 80G drive filled he let me add a second and migrate /home without a hiccup. His nightly incremental backups from rdiff-backup saved me numerous times when I realized I'd deleted an email I still needed. When his disks filled with logs he still let me ssh in.
He never got an OS upgrade or maintenance reboot, yet somehow warded off worms and attacks. At one point he had more than 500 days uptime before a power-failure robbed him of it. When sudden power events did force a restart he never failed to boot, or required intervention in single user mode. His not-journaling ext3 file system just dealt with it.
Ry4an.org II is survived by a linode box. His two drives will be interred in a safe deposit box as backups. His body has been donated to the Hennepin County Hazardous Waste Recycling Facility. In lieu of flowers donations may be made to the EFF.

Ancient Content Warnings
I just rebuilt the ry4an.org server, and as part of the migration I realized a still had a lot of very old, almost embarrassing content online. I took the broken or not-conceivably interesting stuff off-line and am serving up 410 GONE responses for it.
There exists, however, a broad swath of stuff that's not yet entirely useless, but is more than ten years old and not stuff I would likely post today. For all of these pages I've left the content up, but you first have to click through a modal dialog warning you you're looking at very old stuff I don't necessarily endorse. That pop up looks like this:
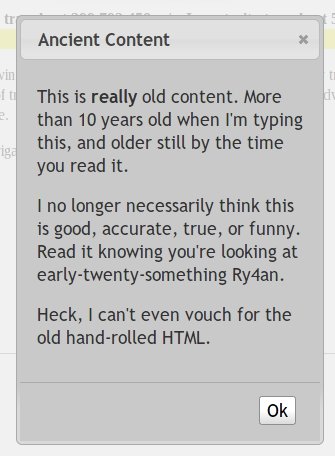
An example can be found here: https://ry4an.org/rrr/ . (Though, if anyone still wants to race from point to point in the twin cities during the worst of rush hour I still think it's an awesome idea.)
Being the sort of person that I am I automated the process of adding those warnings to anything that hasn't been modified in at least 10 years. So, if you got an ancient content warning when viewing this page: Hello 2021!
If you follow a link or bookmark to ry4an.org and you get a 404 Not Found, let me know. Everything should either still be there or should give a 410 GONE so you know it's not there on purpose.
Syntax Highlighting and Formulas for Blohg
I'm thus far thrilled with blohg as a blogging platform. I've got a large post I'm finishing up now with quite a few snippets of source code in two different programming languages. I was hoping to use the excellent SyntaxHighlighter javascript library to prettify those snippets, and was surprised to find that docutils reStructuredText doesn't yet do that (though some other implementations do).
Fortunately, adding new rendering directives to reStructuredText is incredibly easy. I was able to add support for a .. code mode with just this little bit of Python:
Switching Blogging Software
This blog started out called the unblog back when blog was a new-ish term and I thought it was silly. I'd been on mailing lists like fork and Kragan Sitaker's tol for years and couldn't see a difference between those and blogs. I set up some mailing list archive software to look like a blog and called it a day.
Years later that platform was aging, and wikis were still a new and exciting concept, so I built a blog around a wiki. The ease of online editing was nice, though readers never took to wiki-as-comments like I hoped. It worked well enough for a good many years, but I kept having a hard time finding my own posts in Google. Various SEO-blocking strategies Google employs that I hope never to have to understand were pushing my entries below total crap.
Now, I've switched to blohg as a blogging platform. It's based on Mercurial my version control system of choice and has a great local-test and push to publish setup. It uses ReStructured-Text which is what wiki text became and reads great as source or renders to HTML. Thanks to Rafael Martins for the great software, templates, and help.
The hardest part of the whole setup was keeping every URL I've ever used internally for this blog still valid. URLs that "go dead" are a huge pet peeve of mine. Major, should-know-better sites do this all the time. The new web team brings up brand new site, and every URL you'd bookmarked either goes to a 404 page or to the main page. URLs are supposed to be durable, and while it's sometimes a lot of work to keep that promise it's worth it.
In migrating this site I took a couple of steps to make sure URLs stayed valid. I wrote a quick script to go through the HTTP access logs site for the last few months, looked for every URL that got a non-404 response, and turned them into web requests and made sure that I had all the redirects in place to make sure the old URLs yielded the same content on the staging site. I did the same essential procedure when I switched from mailing list to wiki so I had to re-aim all those redirects too. Finally, I ran a web spider against the staging site to make sure it had no broken internal links. Which is all to say, if you're careful you can totally redo your site without breaking people's bookmarks and search results -- please let me know if you find a broken one.
New UnBlog System
I've switched from a mailing list driven system to a wiki based one for this UnBlog. It's less weird than the mailing list setup was, but it's not exactly moveable type either. It offers RSS feeds and subscriptions, though through entirely different mechanisms than the list did. I think I've moved everything over well enough that there are no dead links into the old space. I ended up using my WikiChump thing modified to handle attachments and create comment pages to populate the data.
Blogging 1990s Style
My good friends Luke (http://justlooking.recursion.org/) and Gabe (http://twol.dopp.net/) are working on a project that archives mailings lists to blogging software. Essentially something that subscribes to lists and gateways to posts in a blog. I politely told them the idea didn't make sense to me and instead advocated just putting a blog-look onto existing mailing list software. This is my attempt to put my money where my mouth is.
Vanity mailing lists are nothing new, and I subscribe to quite a few of them. Usually they're just one person talking about whatever pops into his or her head. One of the best belongs to Kragen Sitaker and can be found here: http://www.canonical.org/~kragen/mailing-lists.html .
Some of the advantages of a vanity mailing list with a blog veneer are:
- Push-model available for those who want to subscribe
- Threaded discussion is integral to the system
- Can create blog entries from any location without special software
Some of the drawbacks are:
- Hard to edit old posts
- To make HTML blog entries I'd need to use a HTML compatible mail client -- which I won't. Long live mutt.
I'm sure there are other benefits and drawbacks that I've yet to identify. I'll mention them as I find them.
Comments
Hallo - Could you share your mhonarc resource file and any other tools you used to make this system?
Thanks -- Sean Roberts
I've attached a tarball containing all the files related to the unblog. You'll notice the add.sh script is effectively short circuited because incremental message adding wasn't working for reasons I never documented well. In fact, there's no real documentation at all, but most of it is pretty straight forward. I'm running with MHonArch v2.6.2.
Thanks.
I am working with a group of friends to maintain a non-profits computer systems. Only problem is that half the team is non-technical, and the other half is "Microsoft Technical" (if you get what I mean).
We currently use a mailing list to communicate, it works wonderfully.
Now I need some way to track all of our work (to keep documentation up-to-date). I want a simple log (or blog) of work, but it must be seemless to add to (no one likes documenting). Can't be ugly and have sucky threading, like mailmans default archives. So a mail list based blog that doesn't require any special marking up of the email to get it into the blog. Oh, and no need to setup a "new post notifier", mailman already does that.
Now off to defeat the evil '.doc' attachment they love to send.
Thanks -- Sean Roberts
I noticed that you only use "Subject" as a reference for comments. Why not use "In-Reply-To" or "References" ? Let me guess... most junk emailers fail to properly use those headers.
I will take idea's from your work and add some other things I have thought of. Like a recent comments sidebar. That would just be a date order listing of posts that aren't in reply to anything, or I could slack and just have the most recent posts by date.
I am still shocked that a full fledged journal/weblog hasn't been built around mailing lists rather than web or blogger API input.
-- Sean Roberts
In-Reply-To and Referenced are used. In fact, they're the only thing that get message firmly linked in the Thread index (https://ry4an.org/unblog/threads.html). Notice how your messages are below the '<possible follow-ups>' marker. That indicates the Subject line indicates they're probably replies, but that no In-Reply-To or Referenced headers were found to link it conclusively with the original. You seem to be using squirrel mail and at least the message to which I'm currently replying is missing them.
> I will take idea's from your work and add some other things I have > thought of. Like a recent comments sidebar. That would just be a date > order listing of posts that aren't in reply to anything, or I could > slack and just have the most recent posts by date. > > I am still shocked that a full fledged journal/weblog hasn't been > built around mailing lists rather than web or blogger API input.
Yeah, I don't get it either. Most of the modern blogging software includes email -> post gateways, but there's no similar accomodation for comments. I'm actually beginning to suspect the Usenet-style NNTP might be the perfect marriage of posting, coments, archiving, reading, etc.
-- Ry4an
I was referring to how your "Post a Comment" are controlled. Just the "Subject". e.g.
<code> <a href="mailto:unblog@ry4an.org?subject=Re: Diplomacy at Sea and a Templated Evolver">Post a Comment</a> </code>
-- Sean Roberts
Ahh, If the mailto: protocol supported setting the In-Reply to and References: header I'd definitely use it to set them in the replies. Then then comments would be better attached. As it is, only people who reply to the actual messages on the email list end up with their comments being firmly attached (as opposed to "possibly" attached). Unfortunately, there isn't a mailer I know of that'll let you set anything but the subject and body in mailto: links.
--Ry4an
Tags
- funny
- java
- people
- python
- mongodb
- scala
- perl
- meta
- mercurial
- home
- security
- ideas-built
- ideas-unbuilt
- software
Contact
Content License

This work is licensed under a
Creative Commons Attribution-NonCommercial 3.0 Generic License.