Tag: perl (Atom feed)
Traffic Analysis In Perl and Scala
I needed to implement the algorithm in Practical Traffic Analysis Extending and Resisting Statistical Disclosure in a hurry, so I turned to my old friend Perl. Later, when time permitted I re-did it in my new favorite language, Scala. Here's a quick look at how a few different pieces of the implementation differed in the two languages -- and really how idiomatic Perl and idiomatic Scala can look pretty similar when one gets past syntax.
Grand Central Direct Dialer
I'm a huge fan of Grand Central's call screening features. It's irksome, however, that they make it hard to dial outward -- sending your GC number instead of your cell number as the caller id. To do so you need to first add the target number to your address book, and often I'm calling someone I don't intend to call again often.
I started scripting up a way around that when I saw someone named Stewart already had.
I wanted to be able to easily dial outbound from my cellphone, so I created a mobile friendly web form around his script. The script requires info you should never give out (username, password, etc.), so you should really download the script and run it on your own webserver.
It also generates a bookmarklet you can drag to your browser's toolbar that will automatically dial any selected/highlighted phone number from your GC Number.
Comments
Only to save someone else the time: The iPhone app, Grand Dialer, does the same thing from an iPhone. Everyone says it's excellent.
Improving Nick Tracking using String Similarity
Years back I wrote an IRC nick tracking script. It's served me well since then, but it has one major annoyance. When people changed their name slightly it would remember that name change, even though the old/new mapping didn't contain any real identity change information.
For example, when Gabe_ became Gabe it would display every message from him as <Gabe_(Gabe)>. That doesn't tell me anything interesting about who Gabe is.
I decided to tweak the tracker to ignore small changes in names. Computers don't think in terms like small they need a way to quantify difference and then see if it exceeds a specified threshold. Fortunately, lots of people have worked on just that problem -- mostly so that spell checkers can present you with a list that's close to the non-word you typed.
When I've worked with close enough strings in the past I've used the Levenshtein_distance as implemented in the String::Approx module or the ancient Soundex algorithm. This time, however, I tried out the String::Trigram module as written by Tarek Ahmed, which implements the method proposed by Angell in this paper. Here's an explanation from String::Trigram's README file:
This consists of splitting some string into triples of
characters and comparing those to the trigrams of some other string. For
example the string kangaroo has the trigrams "{kan ang nga gar aro
roo}". A wrongly typed kanagaroo has the trigrams "{kan ana nag aga gar
aro roo}". To compute the similarity we divide the number of matching
trigrams (tokens not types) by the number of all trigrams (types not
tokens). For our example this means dividing 4 / 9 resulting in 0.44.
Thus far, at a 50% match threshold it's never failed to detect a real change or ignore a minor-change, and if it does I should just be able to notch the match-threshold higher or lower. Great stuff.
The modified script can be viewed here and downloaded here.
Comments
If you wanted to only track nick changes in certain channels you'd add code line this at line 86:
return unless grep /^$chan$/, qw(#channelone #channeltwo #channel3);
I've modified 1.1 with a new /function, trackchan, that allows one to manage a list of channels where they want nick tracking to take place. If the list is empty, tracking will be done in all channels. The following is a unified diff.
What it doesn't do:
- Check to make sure that the channel you're passing in actually conforms to any standard channel naming conventions.
- Check to see if the channel already exists in the list before trying to remove it (though thanks to it just being a simple grep, no errors is returned in any case).
- Check to see if you're adding a duplicate channel to the list (feel free, it doesn't affect the functionality one bit).
- Have an option for printing the channel list. I think I will modify it to just print the channel list in addition to the usage if /trackchan is called with no arguments.
-- Gabe
--- nick-track.pl.orig Thu Dec 22 10:37:34 2005
+++ nick-track.pl.trackchan Thu Dec 22 14:50:30 2005
@@ -22,7 +22,7 @@
use Irssi;
use strict;
use String::Trigram;
-use vars qw($VERSION %IRSSI %MAP);
+use vars qw($VERSION %IRSSI %MAP @CHANNELS);
$VERSION = "1.1";
%IRSSI = (
@@ -47,6 +47,7 @@
'Asrael' => 'Sammi',
'Cordelia' => 'Sammi',
);
+@CHANNELS = qw();
sub call_cmd {
my ($data, $server, $witem) = @_;
@@ -84,6 +85,13 @@
my ($chan, $nick_rec, $old_nick) = @_;
my $nick = $nick_rec->{'nick'};
+ # If channel list is empty, track for all channels.
+ # If channel list is non-empty, track only for channels in list.
+ my $channels = @CHANNELS;
+ if ($channels > 0) {
+ return unless grep /^$chan$/, @CHANNELS;
+ }
+
if (defined $MAP{$old_nick}) { # if a previous mappings exists
if (String::Trigram::compare($nick, $MAP{$old_nick},
warp => 1.8,
@@ -101,6 +109,34 @@
}
}
}
+
+sub trackchan_cmd {
+ my ($data, $server, $witem) = @_;
+ my ($cmd, $channel) = split ' ', $data;
+ my @cmds = qw(add del);
+
+ unless (defined $cmd && defined $channel && map($cmd, @cmds)) {
+ print "Usage: /trackchan [add|del] #channel";
+ return;
+ }
+
+ if ($cmd eq 'add') {
+ push @CHANNELS, $channel;
+ print "$channel added to channel list";
+ }
+
+ if ($cmd eq 'del') {
+ @CHANNELS = grep(!/^$channel$/, @CHANNELS);
+ print "$channel removed from channel list";
+ }
+
+ print "Current channel list:";
+ foreach my $channel (@CHANNELS) {
+ print " $channel";
+ }
+}
+
+Irssi::command_bind trackchan => \&trackchan_cmd;
Irssi::signal_add("message public", \&rewrite);
Irssi::signal_add("nicklist changed", \&nick_change);
Thanks, Dopp, great stuff! -- Ry4an
Isle Royal GPS Data
Earlier this month some friends and I hiked across Isle Royale in lake Superior. Joe kept his GPS running and produced good track points in an odd export format from his Mac software called "Topo". I created a quick conversion script to produce this GPS format data which can be used with the GPS visualizer website to produce images like this:
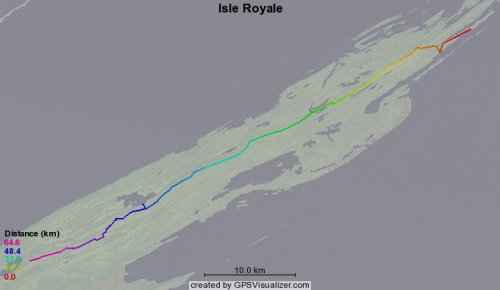
Garble To GPX Track Conversion
For years I've been using garble to pull track and way point data off of my Garmin eTrex GPS. Unfortunately it produces data in a completely non-standard format. In the past I've written a little custom software to turn the garble data into maps.
Now I'm using http://gpsvisualizer.com to produce much nicer maps, but it takes data in the superior GPX format. The GPSBabel software will pull way point data off of Garmin GPSs and puts them into GPX, but it doesn't handle tracks.
So, I needed something that took garble output like:
45.222774, -92.767997 / Sun Apr 10 18:57:32 2005
and turned it into GPX statements like:
<trkpt lat="45.222774" lon="-92.767997"><time>2005-04-10T18:57:32Z</time></trkpt>
this Perl snippet I wrote:
#!/bin/perl -w
use strict;
use Date::Parse;
use Date::Format;
while (<>) {
chomp;
unless (/(\S+), (\S+) \/ (.*)/) {
print STDERR "Unparseable line: '$_'\n";
next;
}
my $when = str2time($3);
my $time = time2str('%Y-%m-%dT%H:%M:%SZ', $when);
print qq|<trkpt lat="$1" lon="$2"><time>$time</time></trkpt>\n|;
}
does the job.
Obscuring MoinMoin Wiki Referrers
When you click on a link in your browser to go to a new web page your browser sends along a Referrer: header, which tells the owner of the site that's been linked to the URL of the site where the link was found. It's a nice little feature that helps website creators know who is linking to them. Referrer headers are easily faked or disabled, but in general most people don't bother, because there's generally no harm in telling a website owner who told you about their site.
However, there are cases where you don't want the owner of the link target to know who has linked to them. We've run into one of these where I work because one of our internal websites is a wiki. One feature of wikis is that the URLs tend to be very descriptive. Pages leaving addresses like http://wiki.internal/ProspectivePartners/ in the Referrer: header might give away more information than we want showing up in someone else's logs.
The usual way to muffle the outbound referrer information from the linking website is to route the user's browser through a redirect. I installed a simple redirect script and figured out I could get MoinMoin, our wiki software of choice, to route all external links through it by inserting this into the moin_config.py file:
url_mappings = {
'http://': 'http://internal/redirect/?http://',
'https://': 'http://interal/redirect/?https://'
}
Now the targets of the links in our internal wiki only see '-' in their referrer logs, and no code changes were necessary.
Comments
I'm working on installing a some what sensitive wiki, so this is interesting.
How does the redirect script remove the referer, though? I couldn't figure that out from the script.
It just does due to the nature of the Referrer: header. When going a GET a browser provides the name of the page where the clicked link was found. When a link on page A points to a redirection script, B, then the browser tells B that the referrer was A. Then the redirect script, B, tells the browser to go to page C -- redirects it. When the browser goes to page C, the real target page, it doesn't send a Referrer: header because it's not following a link -- it's following a redirect. So the site owner of C never sees page A in the redirect logs. S/he doesn't see the address of B in those logs either, because browsers just don't send a Referrer header: at all on redirects. -- Ry4an
There was a little more talk about this on the moin moin general mailing list, including my proposal for adding redirect-driven masking as a configurable moin option. -- Ry4an
Better Random Subject Lines
Earlier I talked about generating random Subject lines for emails. I settled on something that looked like Subject: Your email (1024) . Those were fine, but got dull quickly. By switching the procmail rules to look like:
:0 fhw * ^Subject:[\ ]*$ |formail -i "Subject: RANDOM: $(fortune -n 65 -s | perl -pe 's/\s+/ /g')" :0 fhw * !^Subject: |formail -i "Subject: RANDOM: $(fortune -n 65 -s | perl -pe 's/\s+/ /g')"
I'm now able to get random subject lines with a little more meat to them. They come out looking like: RANDOM: The coast was clear. -- Lope de Vega
However, given that the default fortune data files only provide 3371 sayings that are 65 characters or under the Birthday_paradox will cause a subject collision a lot sooner than with the 2:superscript:15 possible subject lines I had before.
Update: It's been a few weeks since I've had this in place and my principle subject-less correspondent has noticed how eerily often the random subject lines match the topic of the email.
Mail To Wiki Gateway
I wanted a way to quickly append text to Moin Moin wikis. I wrote a Perl script to do just that. It relies on the email address suffix features available in most modern MTAs to get the page name.
Once the procmail recipe included in the accompanying procmail.rc file is in place for the user 'wiki' email sent to wiki-TextHere@somewhere.com will be appended to the TextHere wiki page.
I cheaped out on the formatting and just put the text inside literal/pre blocksblocks. The subject line and from header are retained and displayed.
By default the posts are done under no user, but the included makecookie.pl can be used to create a cookie file that the script will use to persist a wiki login (I tend to use EmailGateway).
It looks like there's been some updating and porting discussion of this script at ScriptMarket/EmailToWikiGateway
History of the World - Attack Probabilities
History of the World is a fine game from Avalon Hill. It's distributed by Hasbro now, and it's one of the rare Avalon Hill games that Hasbro managed to improve when they "cleaned it up".
History of the World uses dice to simulate combat, and they do so in a way so as to intentionally skew the likelihood of success toward the attacker. There are, however, various terrains (mountainous, ocean straight, forest), types of attack (amphibious), bonuses (strong leader, elite troops, forts, weaponry, etc.) which can affect the success rate of an attacker.
While playing last night we tried to estimate the relative merits of the different troop-efficacy modifiers and found that as if often the case with probability it was difficult to agree even on estimates.
As a result I sat down and wrote some quick Perl simulations to find the numbers for all the various scenarios. This wasn't done in the most efficient way possible, but it's accurate. The terms 'win', 'tie', and 'loss' are from the attacker's point of view.
| Attk Dice | Attk Bonus | Def. Dice | Def. Bonus | Win | Tie | Loss |
|---|---|---|---|---|---|---|
| 2 | 0 | 1 | 0 | 57.87% | 16.67% | 25.46% |
| 2 | 0 | 1 | 1 | 41.67% | 16.20% | 42.13% |
| 2 | 0 | 2 | 0 | 38.97% | 22.07% | 38.97% |
| 2 | 0 | 2 | 1 | 22.38% | 16.59% | 61.03% |
| 2 | 0 | 3 | 0 | 28.07% | 24.77% | 47.16% |
| 2 | 0 | 3 | 1 | 12.96% | 15.11% | 71.93% |
| 2 | 1 | 1 | 0 | 74.54% | 11.57% | 13.89% |
| 2 | 1 | 1 | 1 | 57.87% | 16.67% | 25.46% |
| 2 | 1 | 2 | 0 | 61.03% | 16.59% | 22.38% |
| 2 | 1 | 2 | 1 | 38.97% | 22.07% | 38.97% |
| 2 | 1 | 3 | 0 | 52.84% | 19.23% | 27.93% |
| 2 | 1 | 3 | 1 | 28.07% | 24.77% | 47.16% |
| 3 | 0 | 1 | 0 | 65.97% | 16.67% | 17.36% |
| 3 | 0 | 1 | 1 | 49.38% | 16.59% | 34.03% |
| 3 | 0 | 2 | 0 | 47.16% | 24.77% | 28.07% |
| 3 | 0 | 2 | 1 | 27.93% | 19.23% | 52.84% |
| 3 | 0 | 3 | 0 | 35.23% | 29.54% | 35.23% |
| 3 | 0 | 3 | 1 | 16.69% | 18.54% | 64.77% |
| 3 | 1 | 1 | 0 | 82.64% | 9.65% | 7.72% |
| 3 | 1 | 1 | 1 | 65.97% | 16.67% | 17.36% |
| 3 | 1 | 2 | 0 | 71.93% | 15.11% | 12.96% |
| 3 | 1 | 2 | 1 | 47.16% | 24.77% | 28.07% |
| 3 | 1 | 3 | 0 | 64.77% | 18.54% | 16.69% |
| 3 | 1 | 3 | 1 | 35.23% | 29.54% | 35.23% |
Attached is the script and the same output in various formats.
University of MN Magic Number Guessing
Back when I started at the University of Minnesota in 1995 the course registration system was terminal/telnet based. Students would register using a clumsy mainframe-style form interface. When a class a student wanted was full or required unsatisfied prerequisites, the student come supplicant would go to the department to beg for a "magic number" which, when input into the on-line registration system, would allow him or her admission into the course.
Magic numbers were five digits long and came pre-printed in batches of about sixty when provided to departmental secretaries. For each course there existed a separate printed list of magic numbers. As each number was handed out to a student it was crossed off the list, indicating that they were single-use in nature.
As getting one's schedule "just so" was nearly impossible given the limited positions in some courses, and if I recall correctly being particularly frustrated that the only laboratory session remaining open for one of my courses was late on Friday afternoons, I set out to beat the magic number system.
The elegant solution would have been to find the formula used to test a five digit number against the course information to see if it was a match. This, however, presupposes that there existed an actual test and not just a list of sixty numbers for each course. Given than the U of MN had 1000s of courses it's certainly hoped that they didn't design a system requiring the generation and storage of 60,000 numbers, but one never knows. A day spent playing Bletchley Park with previously received magic numbers and their corresponding course numbers found no easily discernible pattern, and given the lack of certainty that there even was one I decided to move on.
A five digit magic number leaves only 100,000 possible options. With at least sixty available per course that's a one in 1,666 chance per guess. Given average luck that's only 833 expected guesses before a solution hits. Tedious when done manually, but no problem for a script.
At the time, Fall 1997, my script-fu was weak, but apparently sufficient. I used Perl (poorly) to create a pair of scripts that allowed me to login, attempt to register for a course, and then kick off a number guesser. In case the registration system had been programmed to watch for sequential guesses, I pre-randomized all 100,000 possible magic numbers and tried them in that order. Given that they didn't even bother to watch for thousands of failed guesses in a row this was probably overkill, but better safe than sorry.
The script worked. My friends and I got our pick of courses for the next few quarters, and despite my boastful nature news never made it back to the U that such a thing was occurring. We only stopped using the system when the telnet based registration was retired in favor of a web based system. Knowing what I now do about automating HTTP form submissions, the web based system would likely have been even easier to game.
The biggest glitch in the system was the fact that magic numbers were single use. Whenever I "guessed" a magic number that was later given by the department to a student, that student's number wouldn't work. However, being given non-working magic numbers was a fairly regular occurrence and certainly not a cause for further investigation on the part of the department. Indeed, the frequency with which my friends and I were given non-working magic numbers leads one to wonder if others weren't doing exactly as we were either using scripts, manual guessing, or by riffling the secretaries' desks.
I've attached a screen-shot of the script in progress from an actual course registration in 1998. Also attached are all the files necessary for use of the original script though since the target registration system is long gone they're only of historical interest. Looking at the code now, I'm really embarrassed at both the general style and the overall design. The open2 call, the Expect module, or at least named pipes would have made everything much cleaner. Still it worked well enough, and I never got caught which is what really matters.
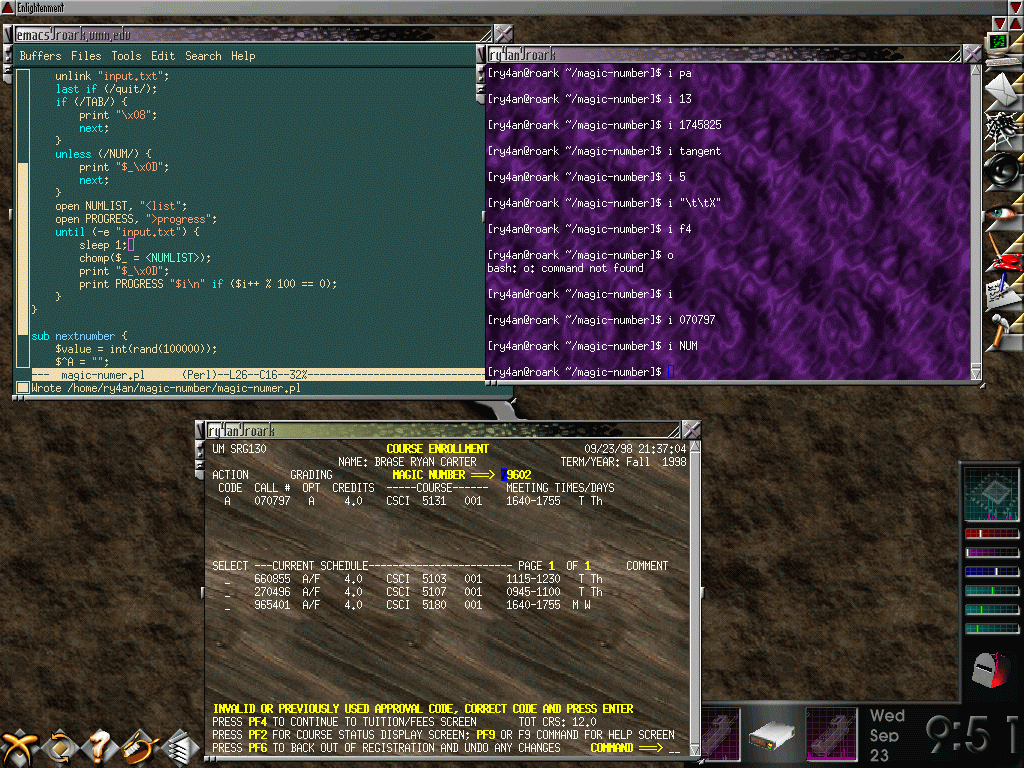
Comments
Doh, had no idea those attachment were as big as they were. Sorry 'bout that. -- Ry4an
Hang on a sec...you're using Emacs in that screenshot! -- Luke Francl
I know, I didn't see the light and switch to vi until 1998. Goes to show you're never too late to repent. -- Ry4an
Poker Timer Configuring Launcher
I got sick of having to edit the launch file whenever I ran my Poker Timer (https://ry4an.org/unblog/msg00038.html), so I wrote a quick CGI that generates a JNLP file which launches the app with the specified settings. You'll need to have a 1.2 or higher Java Virtual Machine installed (http://java.com).
So we've got a Perl interpreter dynamically producing a JNLP file that tells a Java Virtual Machine what to do. Talk about an unholy alliance.
The timer can be run at:
https://ry4an.org/pokertimer/
PokerBot in IRC
I said I wasn't going to do it, but I ended up doing so anyway. I've written a Poker dealing IRC bot. It's not terribly modular and it only supports TexasHold'em, but it works. It requires Perlbot 1.9.5 which is available on source forge. Here's an excerpt from play:
<Dealer> Board now shows: AH 2C 9D 2D <Dealer> joe, action is to you. Current bet is 0. * joe bets 20 <Dealer> joe bets 20. <Dealer> Ry4an, action is to you. Current bet is 20. * joe peeks * Ry4an calls <Dealer> Ry4an calls. <Dealer> Board now shows: AH 2C 9D 2D 2H <Dealer> joe, action is to you. Current bet is 0. * joe checks <Dealer> joe checks. <Dealer> Ry4an, action is to you. Current bet is 0. * Ry4an checks <Dealer> Ry4an checks. <Dealer> joe has been called and shows: 7D 8D <Dealer> Ry4an shows 10C 6C and wins 70 with Trips (2 A T)
Anyway, I've attached the code in case someone wants to take it and make it better or update it to the newer versions of perlbot.
Net::Friends for GPSDrive
GPSDrive (http://www.gpsdrive.de/) is nifty software for Linux that turns a laptop and a cheap GPS receiver into a vehicle navigation system. It displays maps, records tracks, logs speed traps, and all the other little features you'd expect in a system trying to divert your eyes from the road.
It also sports a built-in system for networking with other GPSDrive enabled systems on the road to mutually plot one another's locations. The system, called friendsd, uses a simple UDP server to record and report the position, speed, and heading of other reporting systems on the same server. Of course, this reporting only works if the laptop has access to the Internet but with the various cellular and wi-fi systems available that's not so much a stretch.
I've got a silly little project in the works for using friendsd in a manner other than its original intent, but I needed to be able to interact with it using something other than GPSDrive as the client. To that end I wrote up a little Perl module, Net::Friends (attached), that provides for basic reporting to and querying from friendsd servers. I think it game out pretty well.
IRC Nickname Tracking Script
Being a telecommuter, the closest thing I have to an office is an IRC channel. IRC (Internet Relay Chat) is like a chat room minus the emoticons and pedophiles. While normally the office IRC channel is the very embodiment of maturity, there are two silly things about it that have always annoyed me. The first being that everyone gets to pick their own name, and the second being they can change their names at will.
When everyone can pick their own name you end up with a lot of all-lowercase, powerful sounding names for people you think of as Jim and Bob. If everyone has their own terminal on which they're viewing the channel's discourse there's no reason why we can't all see each other referenced by whatever name we're most comfortable calling the person.
Worse yet is the ability for everyone to change their names. Occasionally, and I've no idea what triggers it, everyone will start switching names willy-nilly to new and sometimes each other's names. This is like going to a costume party where everyone keeps switching masks every few minutes -- eventually someone's gonna kiss someone else's girlfriend.
Because I'm cantankerous and have too much time on my hands, I wrote I little script for the excellent Irssi IRC client I use ( http://irssi.org/ ) that mitigates the hassle from both of the bits of silliness mentioned above. Using my script I can issue commands of the form "/call theirnick whatIcallThem" and from then all messages from the person who was using the nickname "theirnick" will now show up as from "whatIcallThem", and it will do so regardless of how many times they change their nickname.
Is it perfect? No. The people in the channel still refer to one another by their nicknames so I still have to decode nick -> human mappings in my head, but at least not so frequently. At any rate, the script is attached. It is known to work with Irssi v0.8.6.
Comments
This script has been updated in a recent entry.
Email to SMS Conversion
There's a program on freshmeat called email2sms (http://freshmeat.net/projects/email2sms/) that runs emails through a series of filters until they're short enough to be sent to a cell phone as a SMS message -- which typically have a maximum length of 150 characters. The script is mostly just a wrapper around the nifty Lingua::EN::Squeeze Perl module.
Squeeze takes English text and shortens it aggressively using all manner of abbreviations. It leaves the text remarkably readable for being about half its original length.
I ran the email2sms script for just a few weeks before running into a problem where an address sent to me by a friend was mangled past the point of usefulness. I figured that the best fix for that problem was to enlist the sender to evaluate the suitability of the compressed text.
To achieve that I added a feature to email2sms wherein a copy of the compressed message is sent back to the original sender along with a request that if important details were lost from the message during the compression process that they shorten the message themself and re-send it or send it to an alternate email address I provide on which no compression is done. The reply system has worked out quite well, and in the three years I've had it in place there have been a few circumstances were a human initiated re-send has saved an otherwise mangled message.
Attached is my version of the email2sms script, the configuration files I use with it, and a procmail recipe to invoke it. For fun here's the text of this post compressed by Lingua::EN::Squeeze.
ThersProgramOnFrshmatCllEmal2sm(URL/)RunEmalThrghSreOfFiltUntlT/reShor tEnoghToBeSntToCllP8AsSMSMsg--W/TpclyHvMaxLengthOf150Chr.ScriptIsMostl yJstWrappArondNiftyLng::EN::sqzPrlMod.SqzTakEngTxtAndShortenItAggresvl yUsngAllMannOfAbbrevitonItLeaveTxtRemrkblyRedble4BngAbotHlfItsOrgnalLe ngthIRanEmal2smScript4JstFewWekBfreRunnngIntPrbWherAddresSntToMeByFrnd WasManglPstPntOfUsflnesIFigurBstFix4PrbWasToEnlistSendToEvaluSuitablty OfCompressTxtToAchiveIAdddFetreToEmal2smWhrinCopyOfCompressMsgIsSntBck ToOrgnalSendAlongW/RqestIfImportantDtilWerLstFromMsgDurngComprsonProcT /ShortenMsgThemselfAndRe-sndItOrSndItToAlternEmalAddresIPrvdeOnW/NoCom prsonIsDon.ReplyStmHasWrkOutQuite,AndInThreeYYIveHadItInPlacTherHvBenF ewCircmstnceWerHumanInttedRe-sndHasSavOthrwseManglMsgAttachedIsMyVerOf Emal2smScript,ConfigurtonFilIUseW/It,AndPrcmilRcpeToInvokeIt.4FunHersT xtOfThiPstCompressByLng::EN::sqz
Canoeing with a GPS Unit
This weekend I had a great time canoeing with six friends. We camped, swam, paddled, drank and just generally goofed around for a weekend. Two of us had brought along Garmin eTrex GPS units which I'd not previously had when canoeing. They really added a lot.
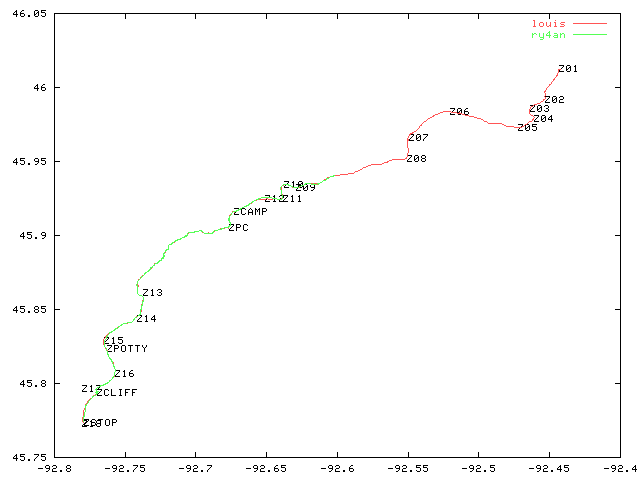
I built an 18 point route approximating our course before hand and loaded them into the GPSs. With that info and the GPS's natural data collection we were able to always know our current speed, average speed (3.2 mph), max speed (mine = 10.5 mph), distance paddled (total = 29.1 miles), and elapsed time (10 hours 31 minutes of paddling).
When we got back I took the GPS units and dumped their track history data to my computer. Using the attached garbleplot.pl script, it made the attached image of our course. The x and y scales are internally consistent in the image, but can't be compared with each other as the distance represented by a degree longitude and that of a degree latitude are different anywhere but the equator. The GPS data has a much higher level of precision than the pixel resolution in the image can show. At a higher zoom level the red and green lines would should Louis's canoe cutting a nice straight line down the river while mine zig zagged its way along the same general course.
Email Response Times
I get and send a lot of email. Many of the emails I send are responses to emails I received. When I respond to email I almost always quote the email to which I'm responding, and when I do my email client (mutt) inserts a line like:
On Thu, Jan 02, 2003 at 11:40:25AM -0600, Justin Chapweske wrote:
Knowing the time of the original message and the time of my reply provides enough information to track my response times to email. I used the inbound message ids to make sure only the first reply to an email was counted.
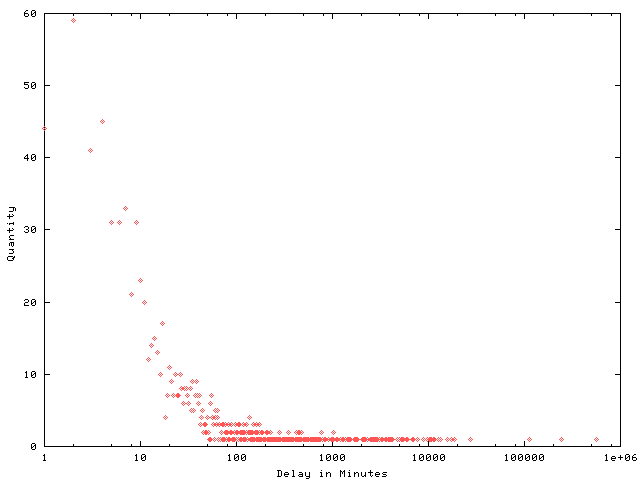
I whipped up a little Perl script to extract some stats and create a histogram. The script and histogram are attached. Here are some of the stats I found:
- Of the 1888 emails I've sent during calendar 2003 thus far 1128 of them were replies
- My five most common response times in minutes were:
- two minutes: 59 times
- four minutes: 45 times
- one minute: 44 times
- three minutes: 41 times
- seven minutes: 33 times
- My mean response times was 20.3 hours.
- My longest response time was 386 days to some guy from whom I want tobuy a domain.
WikiChump
A chump bot (http://www.w3.org/2001/09/chump/) sits in an IRC (Chat) channel and remembers any URL (web addresses) that people say. It displays them on a web page for later reference. I spend time in #infoanarchy on the freenode network (freenode.org) where someone runs a chump bot whose output is visible here: http://peerfear.org/chump/
A wiki is website anyone can edit. Every page has an edit button on the bottom which anyone can press to edit the page. They grow organically and are great for group collaboration. Some friends and I set one up and track plan most of our group activities using it. The most famous wiki is http://c2.com/cgi-bin/wiki?WikiWikiWeb
I wanted to combine these two resources so that anything said in the IRC channel my friends and I chat in was recorded on the wiki we share. I sat down and Perl script to do just that and it took surprisingly little time. Yay for the HTML::Form module. The output can be seen here: http://www.arioch.org/phpwiki/index.php/WikiChump
Attached is a tarball containing that script.
Mailman Non-Subscriber Message Auto-Rejector
I run a lot of mailing lists on mailman, http://www.list.org/, servers. Most all of these lists are configured so that only list subscribers are allowed to post messages. I do this because these lists get a lot of spam messages that I don't want to get through to all subscribers.
Unfortunately, when a non-subscriber posts they're not automatically rebuffed, but instead I, as the mailing list administrator, get an email asking if I want to approve their message anyway. If I don't answer that question I get get a reminder every 24 hours. The reminders can be turned off, but there are some of mailman's questions that I do want to have brought to my attention (ex: subscribed posters who have exceeded maximum message size, etc.).
What I wanted was a way to configure a mailman list so that non-subscribers get a message explaining why their post isn't being accepted without me having to go click 'reject' on a web form. I started to add this feature to mailman, but that wouldn't really wouldn't help. I can't get source forge or my company to upgrade to the newest version of mailman even if my features gets accepted, and those are my lists that get the most spam.
Instead, I wrote a filter that catches email indicating a non-subscriber user has posted to a list and automatically goes and clicks 'reject' on their message. I've got the auto-clicker coded up pretty carefully such that any pending requests that aren't non-subscriber posts won't get auto-rejected. Also, if there's any sort of error in the process the initial notification message is allowed through.
The whole thing fits into a nice tidy Perl script. It's invoked via procmail and requires the excellent LWP suite of modules available from CPAN. The script is attached.
Surveillance Camera Website
It took most of a weekend to do it, but there's now a nice website for the Minneapolis Surveillance Camera Project at http://sarinity.com . I'll be moving it to its own domain eventually, but that'll be a week or so.
The look is entirely owed to the Open Source Web Design site, http://oswd.org. I love being able to just go snarf a well coded template for a new project. Those people are doing a real service.
The meat of the new site was done in Perl by myself. One can now view camera locations, information, and pictures, report cameras, and upload photos of cameras.
I heard back from the Derek Tonn of tonnhaus design about using the map, and he's understandably interested in seeing how the project comes out and what it's about before he provides the tacit approval implied through the use of his base map. If I need to switch over to another map it shouldn't be a hassle, I just despair finding one as pretty as his.
Update: I've shut down this site.
Surveillance Camera Reporting
I got the surveillance camera location reporting stuff working tonight. It's amazing how easy Perl's CGI.pm can make stupid little web input forms. I'm sure I'll think of some other fields that I want in the data before this thing goes live, but for now this should do nicely: https://ry4an.org/surveillance/report/
The map I'm using is nice, but doesn't include all of downtown, and I still haven't heard back from its creators about getting permission to use it. Since I might have to change maps in the future (or might want to expand project scope) I'm hoping to store the camera locations as GPS coordinates rather than as useless pixel locations.
Toward that end I walked to the four corners of the map tonight while taking GPS readings. I'll import the data later and see if the map is to scale in addition to being aesthetically pleasing. If it is, extracting latitude and longitude data will be a snap given that the spherical nature of the earth can be ignored for areas a small as downtown Minneapolis. If it's not, I'll probably have to find a new map before too many cameras get entered.
Next steps are:
- Coming up with a decent data storage format
- Writing rending code to display the camera data
- Making the website attractive and filled with text
- Begging my friends to help me inventory cameras
None of those should be terribly hard. Who knows within a month or so this might actually be a project worth looking at.
Update: I've shut down this site.
Symlink Re-Creator
At Onion Networks our CVS repository has a lot of symlinks that need to exist within it for builds to work. Unfortunately, CVS doesn't support symbolic links. Both subversion and metacvs support symbolic links but neither of those are sufficiently ready for our needs, so we're stuck with creating links manually in each new CVS checkout.
Sick of creating links by hand, I decided to write a quick shell script that creates a new shell script that recreates the symlinks in the current directory and below. A year or two ago I would have done this in Perl. I love Perl and I think it gets an undeserved bad wrap, but I find I'm doing little one-off scripts in straight shell (well bash) lately as others are more inclined to try them out that way.
Doing this in shell also gave me a chance to learn the getopt(1) command. Getopt is one of those things is you know is always there if you need it, but never get around to using. It's syntax sucks, but I'm not sure I could come up with better, and what they've got works. While writing my script I kept scaling back the number of options my script was going to offer (absolute, relative, etc. all gone) until really I was down to just one argument and could've put off learning getopt for another few years. O'well.
Once I'd written all the option parsing stuff and started with the find/for loop/readlink command that was going to print out the ln commands, I noticed that by using the find command's powerful -printf action I could turn my whole damn script into a single line. At least my extra wordy version has an integrated usage chart.
Here's the one line version:
find . -type l -printf 'ln -s %l %pn'
Attached is my script that does pretty much the same thing.
False Point Filtering on the Mimio
I'm trying not to have all the projects and ideas posted to this list be computer related, but I guess that's where I expend most of my creative energy. I bought a Mimio electronic white board (http://mimio.com) cheap on eBay ($40), and while the Windows software for it is reported to be quite good, the Linux software options ranged from vapor to unusable. I did, however, find some Perl code that handled protocol parsing (the tedious part), so I started with that.
The white board part of it was largely uninteresting, but one fun problem cropped up. The Mimio infrequently reported false pen position data that caused the resulting image to have some terrible lines across it. An example of the out with the bad data can be found in the attached unfiltered.png image.
To filter out the bad points I started by tossing out any line segments that were longer/straighter/faster than a human should reasonably be drawing. Essentially I was taking the first derivative of the position data and discarding anything with too high a speed.
Always one to go too far I modified my filter so it could take Nth order derivatives. I ended up configuring it to take the first four derivatives of position (velocity, acceleration, jerk, jounce[1]). I could've set it to 100 or so, but I figured with the time resolution I had I was already pushing it.
I experimentally arrived at threshold levels for the scalar magnitudes of each derivative using the ophthalmologist technique ("this or this", "this or this"). The end result for the same image can be viewed in filtered.png. The missing lines that should be there correspond to when I didn't press the pen down hard enough and are actually missing in the unfiltered image as well. It's still not perfect, but it's good enough for me, unless someone else has a cool filtering idea I can try.
I've attached the tarball for the software for posterity. If you're using it email me first -- I might have a more current unreleased version.
[1] http://math.ucr.edu/home/baez/physics/General/jerk.html
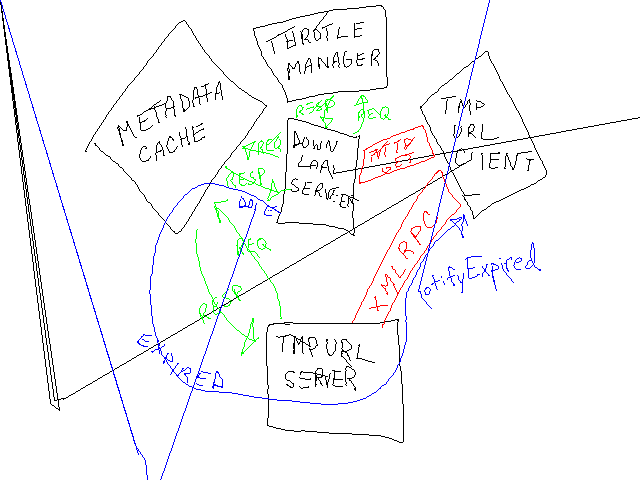
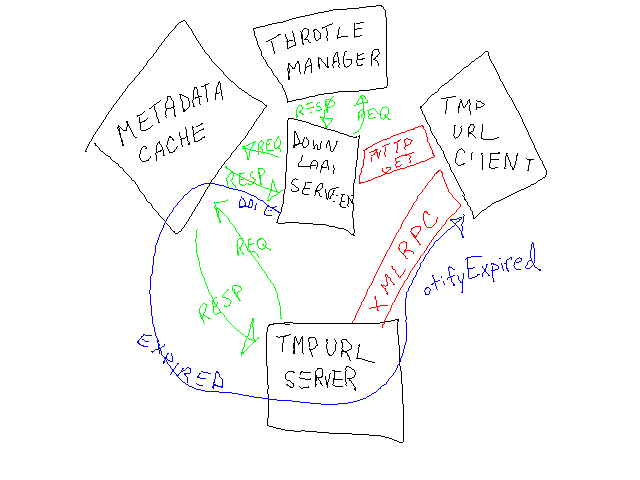
Blogging 1990s Style
My good friends Luke (http://justlooking.recursion.org/) and Gabe (http://twol.dopp.net/) are working on a project that archives mailings lists to blogging software. Essentially something that subscribes to lists and gateways to posts in a blog. I politely told them the idea didn't make sense to me and instead advocated just putting a blog-look onto existing mailing list software. This is my attempt to put my money where my mouth is.
Vanity mailing lists are nothing new, and I subscribe to quite a few of them. Usually they're just one person talking about whatever pops into his or her head. One of the best belongs to Kragen Sitaker and can be found here: http://www.canonical.org/~kragen/mailing-lists.html .
Some of the advantages of a vanity mailing list with a blog veneer are:
- Push-model available for those who want to subscribe
- Threaded discussion is integral to the system
- Can create blog entries from any location without special software
Some of the drawbacks are:
- Hard to edit old posts
- To make HTML blog entries I'd need to use a HTML compatible mail client -- which I won't. Long live mutt.
I'm sure there are other benefits and drawbacks that I've yet to identify. I'll mention them as I find them.
Comments
Hallo - Could you share your mhonarc resource file and any other tools you used to make this system?
Thanks -- Sean Roberts
I've attached a tarball containing all the files related to the unblog. You'll notice the add.sh script is effectively short circuited because incremental message adding wasn't working for reasons I never documented well. In fact, there's no real documentation at all, but most of it is pretty straight forward. I'm running with MHonArch v2.6.2.
Thanks.
I am working with a group of friends to maintain a non-profits computer systems. Only problem is that half the team is non-technical, and the other half is "Microsoft Technical" (if you get what I mean).
We currently use a mailing list to communicate, it works wonderfully.
Now I need some way to track all of our work (to keep documentation up-to-date). I want a simple log (or blog) of work, but it must be seemless to add to (no one likes documenting). Can't be ugly and have sucky threading, like mailmans default archives. So a mail list based blog that doesn't require any special marking up of the email to get it into the blog. Oh, and no need to setup a "new post notifier", mailman already does that.
Now off to defeat the evil '.doc' attachment they love to send.
Thanks -- Sean Roberts
I noticed that you only use "Subject" as a reference for comments. Why not use "In-Reply-To" or "References" ? Let me guess... most junk emailers fail to properly use those headers.
I will take idea's from your work and add some other things I have thought of. Like a recent comments sidebar. That would just be a date order listing of posts that aren't in reply to anything, or I could slack and just have the most recent posts by date.
I am still shocked that a full fledged journal/weblog hasn't been built around mailing lists rather than web or blogger API input.
-- Sean Roberts
In-Reply-To and Referenced are used. In fact, they're the only thing that get message firmly linked in the Thread index (https://ry4an.org/unblog/threads.html). Notice how your messages are below the '<possible follow-ups>' marker. That indicates the Subject line indicates they're probably replies, but that no In-Reply-To or Referenced headers were found to link it conclusively with the original. You seem to be using squirrel mail and at least the message to which I'm currently replying is missing them.
> I will take idea's from your work and add some other things I have > thought of. Like a recent comments sidebar. That would just be a date > order listing of posts that aren't in reply to anything, or I could > slack and just have the most recent posts by date. > > I am still shocked that a full fledged journal/weblog hasn't been > built around mailing lists rather than web or blogger API input.
Yeah, I don't get it either. Most of the modern blogging software includes email -> post gateways, but there's no similar accomodation for comments. I'm actually beginning to suspect the Usenet-style NNTP might be the perfect marriage of posting, coments, archiving, reading, etc.
-- Ry4an
I was referring to how your "Post a Comment" are controlled. Just the "Subject". e.g.
<code> <a href="mailto:unblog@ry4an.org?subject=Re: Diplomacy at Sea and a Templated Evolver">Post a Comment</a> </code>
-- Sean Roberts
Ahh, If the mailto: protocol supported setting the In-Reply to and References: header I'd definitely use it to set them in the replies. Then then comments would be better attached. As it is, only people who reply to the actual messages on the email list end up with their comments being firmly attached (as opposed to "possibly" attached). Unfortunately, there isn't a mailer I know of that'll let you set anything but the subject and body in mailto: links.
--Ry4an
Tags
- funny
- java
- people
- python
- mongodb
- scala
- perl
- meta
- mercurial
- home
- security
- ideas-built
- ideas-unbuilt
- software
Contact
Content License

This work is licensed under a
Creative Commons Attribution-NonCommercial 3.0 Generic License.