When I start up the shower it's the wrong temperature and adjusting it to the right temperature takes longer in this apartment than it has in any home in which I've previously lived. I wanted to blame the problem on the low flow shower head, but I'm having a hard time doing it. My thinking was that the time delay from when I adjust the shower to when I actually feel the change is unusually high due to the shower head's reduced flow rate.
OS X Linux Clipboard Sharing
My primary home machine is a Linux deskop, and my primary work machine is an OSX laptop. I do most of my work on the Linux box, ssh-ed into the OS X machine -- I recognize that's the reverse of usual setups, but I love the awesome window manager and the copy-on-select X Window selection scheme.
My frustration is in having separate copy and paste buffers across the two systems. If I select something in a work email, I often want to paste it into the Linux machine. Similarly if I copy an error from a Linux console I need to paste it into a work email.
NFC PayPass Rick Roll
NFC tags are tiny wireless storage devices, with very thin antennas, attached to poker chip sized stickers. They're sort of like RFID tags, but they only have a 1 inch range, come in various capacities, and can be easily rewritten. If the next iPhone adds a NFC reader I think they'll be huge. As it is they're already pretty fun and only a buck each even when bought in small quantities.
Word Star Retaliation
WordStar was the first word processor I ever used. It was non-WYSIWYG, and it was good. I haven't used it since the mid 80s, but I haven't used MS Word since the mid 90s either.
Sometimes I am sent .doc or .docx files, and usually I can figure out what's inside them using OS X Preview or Google Docs, but it's never perfect and frequently numbered lists get renumbered, which makes discussing the docs on the phone particularly hard.
Mercurial Chart Extension
Back in 2008 I wote an extension for Mercurial to render activity charts like this one:
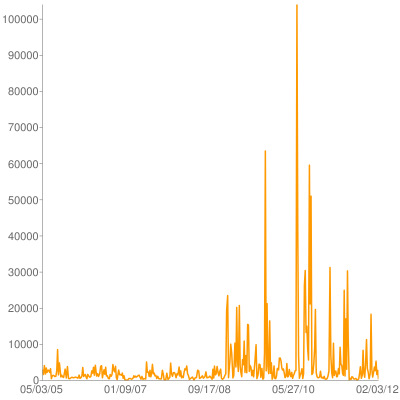
Yesterday I finally got around to updating it for modern Mercurial builds, including 2.1. It's posted on bitbucket and has a page on the Mercurial wiki. It uses pygooglechart as a wrapper around the excellent Google image chart API.
I really like the google image charts becuse the entire image is encapsulated as a URL, which means they work great with command line tools. A script can output a URL, my terminal can make it a link, and I can bring it up in a browser window w/o ever really using a GUI tool at all.
Minneapolis Surveillance Camera Project Shut Down
Now that I no longer live in Minneapolis it seems a fine time to shut down the Minneapolis Surveilance Camera Project I launched in 2003.
At peak it got mentioned in a few strib articles, was written about in the downtown journal, and got a lot of hits from computers within city and county government. After my initial inventory walk most of the camera additions came in via the website from strangers. More of the reports had photos of the cameras once everyone had a camera in their phone.
Eulogy For a Good Server
Two days ago I powered down a good server for the first time in years and the last time ever. It doesn't compare to euthanizing a pet, but it still made me more sad than I expected. Below is a remembrance. I've made the server male because once you've gotten so silly as to write a eulogy for a server you might as well go all out.
Ry4an.org II was a good server. In 2001 his Pentium III hardware was already old -- corporate castoff acquired for free. He took a Fedora install without any configuration hassles and always assigned the same ethX numbers to each of his three PCI NICs, without aliases in the modules.conf, which Ry4an.org I could never get right.
Posthumous Key Revocation
I've just emptied out my safe deposit box for the move, and thought I'd re-post this:
If you hear I've died someone who knows their way around gpg should ask Kate for the CD pictured below. It'll be in a safe deposit box that's in my name, and she'll have access after my death. There's a key revocation certificate with reason 'death' on the CD and a printed ASCII-armored version too since the odds of us being able to read CDs in a few decades is approximately nil.
Miscellaneous Open Source Contributions
I'll take Mercurial over git any day for all the reasons obvious to anyone who's really used both of them, but geeyah github sure makes contributing to projects easy. At work we had a ten minute MongoDB upgrade downtime turn into two hours, and when we finally figured out what deprecated option was causing the daemon launch to abort, rather than grouse about it on Twitter (okay, I did that too) I was able to submit a one line patch without even cloning down the repository that got merged in.
Ancient Content Warnings
I just rebuilt the ry4an.org server, and as part of the migration I realized a still had a lot of very old, almost embarrassing content online. I took the broken or not-conceivably interesting stuff off-line and am serving up 410 GONE responses for it.
There exists, however, a broad swath of stuff that's not yet entirely useless, but is more than ten years old and not stuff I would likely post today. For all of these pages I've left the content up, but you first have to click through a modal dialog warning you you're looking at very old stuff I don't necessarily endorse. That pop up looks like this: