Word Star Retaliation
WordStar was the first word processor I ever used. It was non-WYSIWYG, and it was good. I haven't used it since the mid 80s, but I haven't used MS Word since the mid 90s either.
Sometimes I am sent .doc or .docx files, and usually I can figure out what's inside them using OS X Preview or Google Docs, but it's never perfect and frequently numbered lists get renumbered, which makes discussing the docs on the phone particularly hard.
To date I've been requesting .pdfs instead, but yesterday I tried just responding with a .ws3 file. The recipient asked for a conversion to .pdf (since they didn't have WordStar and a twenty year old machine on which to run it). I guess we'll see if he remembers to send .pdf the first time next time.
I couldn't find a way to generate .ws3 files, so I just gave a .rtf file the .ws3 extension and broke the magic number.
Mercurial Chart Extension
Back in 2008 I wote an extension for Mercurial to render activity charts like this one:
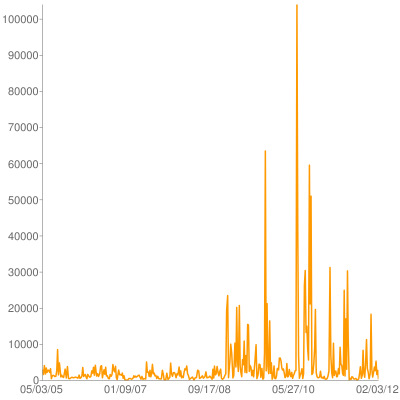
Yesterday I finally got around to updating it for modern Mercurial builds, including 2.1. It's posted on bitbucket and has a page on the Mercurial wiki. It uses pygooglechart as a wrapper around the excellent Google image chart API.
I really like the google image charts becuse the entire image is encapsulated as a URL, which means they work great with command line tools. A script can output a URL, my terminal can make it a link, and I can bring it up in a browser window w/o ever really using a GUI tool at all.
If I take any next step on this hg-chart-extension it will be to accept revsets for complex secifications of what changesets one wants graphed, but given that it took me two years to fix breakage that happened with version 1.4 that seems unlikely.
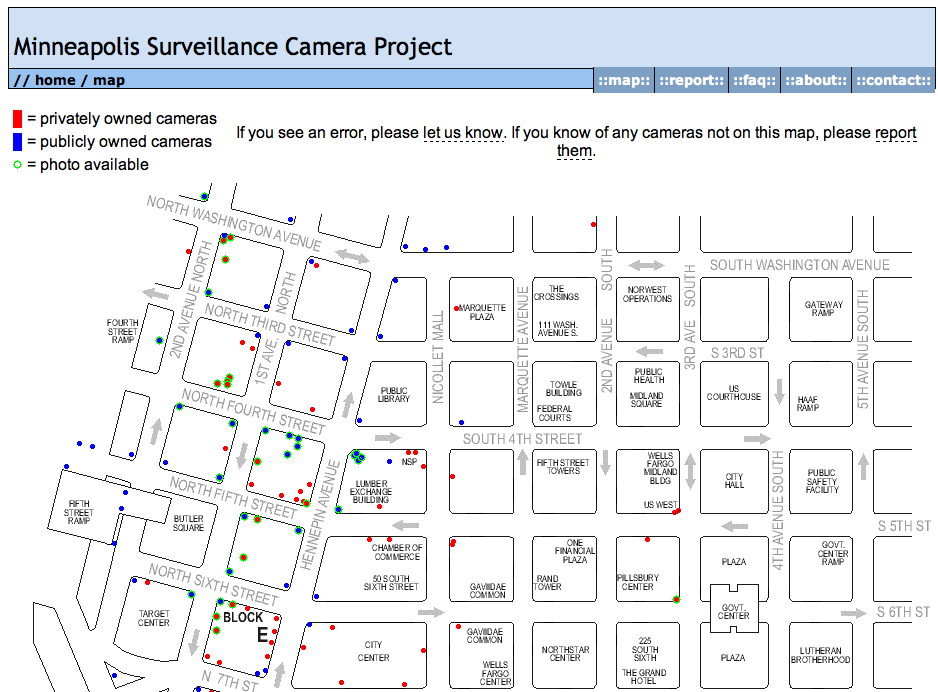
Minneapolis Surveillance Camera Project Shut Down
Now that I no longer live in Minneapolis it seems a fine time to shut down the Minneapolis Surveilance Camera Project I launched in 2003.
At peak it got mentioned in a few strib articles, was written about in the downtown journal, and got a lot of hits from computers within city and county government. After my initial inventory walk most of the camera additions came in via the website from strangers. More of the reports had photos of the cameras once everyone had a camera in their phone.
The whole idea of trying to inventory public and private cameras in public spaces seems silly now. One might as well start the Minneapolis Atom Inventory project -- they're just as plentiful and hard to spot.
If anyone would like the mpls-watched.org domain for any reason let me know. It expires in June and I'm happy to transfer it to someone with a use for it. The content still exists within archive.org.
Eulogy For a Good Server
Two days ago I powered down a good server for the first time in years and the last time ever. It doesn't compare to euthanizing a pet, but it still made me more sad than I expected. Below is a remembrance. I've made the server male because once you've gotten so silly as to write a eulogy for a server you might as well go all out.
Ry4an.org II was a good server. In 2001 his Pentium III hardware was already old -- corporate castoff acquired for free. He took a Fedora install without any configuration hassles and always assigned the same ethX numbers to each of his three PCI NICs, without aliases in the modules.conf, which Ry4an.org I could never get right.
Ry4an.org II ran headless in dusty, cat-fur-filled environs for ten years without ever experiencing a hardware failure of any sort. At age five he moved from a hot closet to a cool basement with less reliable power. He never got the UPS I promised him.
He ran Postfix and Apache for tens of domains. He ran MySQL for Bugzilla and Gallery. He ran dhcpd for both internal and dmz network segments with his iptables keeping them properly isolated. He routed packets to and from a business class connection with the world. He handled two boingboing-ings with aplomb. My mutt and irssi screen sessions never died. He earned his static IP.
When his 80G drive filled he let me add a second and migrate /home without a hiccup. His nightly incremental backups from rdiff-backup saved me numerous times when I realized I'd deleted an email I still needed. When his disks filled with logs he still let me ssh in.
He never got an OS upgrade or maintenance reboot, yet somehow warded off worms and attacks. At one point he had more than 500 days uptime before a power-failure robbed him of it. When sudden power events did force a restart he never failed to boot, or required intervention in single user mode. His not-journaling ext3 file system just dealt with it.
Ry4an.org II is survived by a linode box. His two drives will be interred in a safe deposit box as backups. His body has been donated to the Hennepin County Hazardous Waste Recycling Facility. In lieu of flowers donations may be made to the EFF.

Posthumous Key Revocation
I've just emptied out my safe deposit box for the move, and thought I'd re-post this:
If you hear I've died someone who knows their way around gpg should ask Kate for the CD pictured below. It'll be in a safe deposit box that's in my name, and she'll have access after my death. There's a key revocation certificate with reason 'death' on the CD and a printed ASCII-armored version too since the odds of us being able to read CDs in a few decades is approximately nil.

Miscellaneous Open Source Contributions
I'll take Mercurial over git any day for all the reasons obvious to anyone who's really used both of them, but geeyah github sure makes contributing to projects easy. At work we had a ten minute MongoDB upgrade downtime turn into two hours, and when we finally figured out what deprecated option was causing the daemon launch to abort, rather than grouse about it on Twitter (okay, I did that too) I was able to submit a one line patch without even cloning down the repository that got merged in.
On the more-substantial side I fixed some crash bugs in dircproxy. It had been running rock solid for me for a few years, but a recent libc upgrade that added some memory checking had it crashing a few times a day. Now (with the help of Nick Wormley) I was able to fix some (rather egregious) memory gaffs. I guess this is the oft trumpeted advantage of open source software in the first place -- I had software I counted on that stopped working and I was able to fix. Really though it was just fun to fire up gdb for the first time in ages.
Finally, I was able to take some hours at work and contribute a cookbook for chef to add the New Relic monitoring agent to our many ec2 instances. It may never see a single download, but it's nice to know that if someone wants to use chef to add their systems to the New Relic monitoring display they don't have to start from scratch.
I've been living in a largely open source computing environment for fifteen years, but the barrier to entry as minor contributor has never been so low.
Ancient Content Warnings
I just rebuilt the ry4an.org server, and as part of the migration I realized a still had a lot of very old, almost embarrassing content online. I took the broken or not-conceivably interesting stuff off-line and am serving up 410 GONE responses for it.
There exists, however, a broad swath of stuff that's not yet entirely useless, but is more than ten years old and not stuff I would likely post today. For all of these pages I've left the content up, but you first have to click through a modal dialog warning you you're looking at very old stuff I don't necessarily endorse. That pop up looks like this:
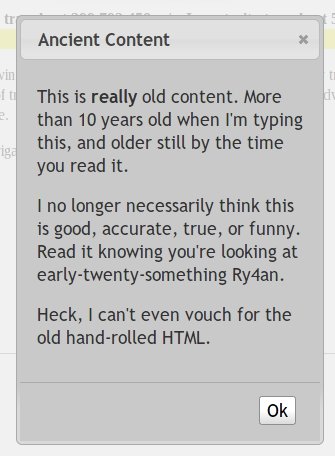
An example can be found here: https://ry4an.org/rrr/ . (Though, if anyone still wants to race from point to point in the twin cities during the worst of rush hour I still think it's an awesome idea.)
Being the sort of person that I am I automated the process of adding those warnings to anything that hasn't been modified in at least 10 years. So, if you got an ancient content warning when viewing this page: Hello 2021!
If you follow a link or bookmark to ry4an.org and you get a 404 Not Found, let me know. Everything should either still be there or should give a 410 GONE so you know it's not there on purpose.
Asynchronous Python Logging
The Python logging module has some nice built-in LogHandlers that do network IO, but I couldn't square with having HTTP POSTs and SMTP sends in web response threads. I didn't find an asynchronous logging wrapper, so I wrote a decorator of sorts using the really nifty monkey patching availble in python:
def patchAsyncEmit(handler):
base_emit = handler.emit
queue = Queue.Queue()
def loop():
while True:
record = queue.get(True) # blocks
try :
base_emit(record)
except: # not much you can do when your logger is broken
print sys.exc_info(
thread = threading.Thread(target=loop)
thread.daemon = True
thread.start(
def asyncEmit(record):
queue.put(record)
handler.emit = asyncEmit
return handler
In a more traditional OO language I'd do that with extension or a dynamic proxy, and in Scala I'd do it as a trait, but this saved me having to write delegates for all the other methods in LogHandler.
Did I miss this in the standard logging stuff, does everyone roll their own, or is everyone else okay doing remote logging in a web thread?
Graduation Form Letter
We just passed through another graduation season, and for the second year running I was able to get by with the same stack of form letters:
Dear _______________________________, My ( Congratulations | Condolences | ___________________ ) on your recent ( Graduation | Eagle Rank | Loss | ___________________ ). It is with ( Great Joy | a Heavy Heart ) that I received the news. I'm sure it took a lot of ( Hard Work | Cigarettes ) to make it happen. I'm sure you'll have a ( great time | good cry ) at the ( open house | wake ) and ( regret | am glad) that I ( can | cannot ) attend. As you move on to your next phase in life please remember: [ ] the importance of hard work [ ] the risks of smoking [ ] there are other fish in the sea [ ] don't have your mom send out your graduation invites -- you're an adult now [ ] ________________________________________ and the value of personal correspondence. Sincerely, your (Cousin | Scoutmaster | Parolee | _____________________), Ry4an Brase Enclosures (1): ( Check | Card | Gift | Best Wishes )
It's available as a Google Doc.
Scholars Walk Time Traveller
The University of Minnesota has a Scholar's Walk which celebrates great persons affiliated with the U and the awards they've won. One display labeled "Historical Giants" remains without any names. Since the U can't reasonably be anticipating any new history, I imagine that four years after installation there's still a committee somewhere arguing about which department gets more names. Not content to wait for committee I decided to add a historical giant of my own -- a time traveller.

The displays are stone boxes with two panes of glass. The outermost pane of glass extends a quarter inch on steel pegs and shows the University branding and the category information. The innermost pane is recessed three inches and contains the names of the honorees. I figured that the outermost glass would provide the necessary gloss, and that any way I could get names behind it and at the right depth would look okay.
I had vinyl lettering made with the wording I wanted and applied it to some laboriously-cut thin lexan. In tests I could I could bend the lexan ninety degrees with just a four inch radius. That flexibility was enough that I could slide the insert in the bottom of the display (the top was sealed against weather).
I showed up early one morning, slipped the insert into place between the two pieces of glass, and was very pleased with the result. The white lettering looked sufficiently etched once behind the shiny outer glass, the fonts and sizes matched nearby displays, and the borders of the lexan insert were nearly invisible. The text is easier to read in the big photo links below, but it lists a physicist with a dis-joint lifespan lauded "for her uniquely important contributions to the understanding of time travel".
Sadly, the insert was removed a few months later, and before someone who can actually take a decent picture got to it. Removing it probably meant disassembling the box to some extent as the very springy plastic insert wouldn't adopt the bend required to make it around the corner without significant coercion not applicable from out side the box.
Here are the bigger pics:
{kind=link}
{kind=link}
Tags
- funny
- java
- people
- python
- mongodb
- scala
- perl
- meta
- mercurial
- home
- security
- ideas-built
- ideas-unbuilt
- software
Contact
Content License

This work is licensed under a
Creative Commons Attribution-NonCommercial 3.0 Generic License.